µ¢ćń½ĀµÅÅĶ┐░Õ¤║õ║ÄRhealstoneńÜäń│╗ń╗¤Õ«×µŚČµĆ¦ńÜ䵥ŗķćÅÕ¤║ÕćåńÜäµĪåµ×Č--R-RhealstoneµĪåµ×ČŃĆé
Õ£©ÕĄīÕģźÕ╝ÅĶĮ»õ╗ČĶ«ŠĶ«ĪÕÆīķøåµłÉõĖŁ’╝īÕ«×µŚČÕżÜõ╗╗ÕŖĪµōŹõĮ£ń│╗ń╗¤ńÜäµĆ¦ĶāĮÕłåµ×ɵś»Ķć│Õģ│ķćŹĶ”üńÜä’╝īÕ«āķ£ĆĶ”üõ┐ØĶ»üÕ║öńö©ńÜ䵌ČķŚ┤ķÖÉÕłČÕŠŚÕł░µ╗ĪĶČ│’╝īÕŹ│µś»Ķ┐ÉĶĪīµŚČķŚ┤õĖŹĶāĮĶČģĶ┐ćÕ║öńö©ńÜ䵌ČķŚ┤ķÖÉÕłČŃĆéõĖ║õ║åķĆēµŗ®µ╗ĪĶČ│ńö©õ║Äńē╣Õ«ÜÕ║öńö©ńÜäÕĄīÕģźÕ╝Åń│╗ń╗¤ńÜäõĖĆõĖ¬ķĆéÕĮōńÜäµōŹõĮ£ń│╗ń╗¤,µłæõ╗¼ķ£ĆĶ”üÕ»╣µōŹõĮ£ń│╗ń╗¤µ£ŹÕŖĪĶ┐øĶĪīÕłåµ×ÉŃĆéĶ┐Öõ║øµōŹõĮ£ń│╗ń╗¤µ£ŹÕŖĪµś»ńö▒ÕĮóµłÉµĆ¦ĶāĮµīćµĀćńÜäÕÅéµĢ░ńĪ«Õ«ÜńÜä’╝īµŚóÕ«ÜńÜäµĆ¦ĶāĮµīćµĀćÕīģµŗ¼õĖŖõĖŗµ¢ćÕłćµŹóµŚČķŚ┤ŃĆüõ╗╗ÕŖĪµŖóÕŹĀµŚČķŚ┤ŃĆüõĖŁµ¢ŁÕ╗ČĶ┐¤µŚČķŚ┤ŃĆüõ┐ĪÕÅĘķćŵĘʵ┤ŚµŚČķŚ┤ŃĆüµŁ╗ķöüĶ¦ŻķÖżµŚČķŚ┤ŃĆüõ┐Īµü»õ╝ĀĶŠōÕ╗ČĶ┐¤ŃĆé
Õģ│õ║ÄÕ«×µŚČµōŹõĮ£ń│╗ń╗¤Õ»╣µĆ¦ĶāĮµīćµĀćĶ┐øĶĪīÕłåµ×É’╝īµś»õĖ║õ║åķĆēµŗ®µ╗ĪĶČ│ńö©õ║Äńē╣Õ«ÜÕ║öńö©ńÜäÕĄīÕģźÕ╝Åń│╗ń╗¤ńÜäµ£Ćõ╝śńÜäµōŹõĮ£ń│╗ń╗¤ŃĆé
Rhealstone
Rhealstoneµś»ń│╗ń╗¤Õ«×µŚČµĆ¦ńÜ䵥ŗķćÅÕ¤║Õćåõ╣ŗõĖĆ’╝īRhealstoneµĆ¦ĶāĮÕ¤║Õćåń©ŗÕ║ŵś»Õ«×µŚČń│╗ń╗¤ńÜäÕģŁõĖ¬Õģ│ķö«µōŹõĮ£ńÜ䵌ČķŚ┤ķćÅĶ┐øĶĪīµōŹõĮ£’╝īĶ┐ÖÕģŁõĖ¬Õģ│ķö«µōŹõĮ£µś»’╝ÜõĖŖõĖŗµ¢ćÕłćµŹóµŚČķŚ┤ŃĆüõ╗╗ÕŖĪµŖóÕŹĀµŚČķŚ┤ŃĆüõĖŁµ¢ŁÕ╗ČĶ┐¤µŚČķŚ┤ŃĆüõ┐ĪÕÅĘķćŵĘʵ┤ŚµŚČķŚ┤ŃĆüµŁ╗ķöüĶ¦ŻķÖżµŚČķŚ┤ŃĆüõ┐Īµü»õ╝ĀĶŠōÕ╗ČĶ┐¤ŃĆéĶ┐ÖÕģŁķĪ╣µōŹõĮ£õĮ£õĖ║RhealstoneńÜäÕģŁõĖ¬ń╗äõ╗Č’╝īµ»ÅõĖ¬ń╗äõ╗ČĶó½ÕŹĢńŗ¼µĄŗķćÅŃĆéńäČÕÉÄÕ░åń╗Åķ¬īń╗ōµ×£ÕÉłÕ╣ČõĖ║ÕŹĢõĖĆńÜ䵥ŗķćÅÕĆ╝’╝īÕŹ│µś»RhealstoneÕĆ╝ŃĆé
| Õ║ÅÕÅĘ | Ķ»┤µśÄ |
|---|---|
| µ¢╣Õ╝Å 1 | ķĆÜńö©Rhealstone |
| µ¢╣Õ╝Å 2 | µ»ÅõĖ¬ń╗äõ╗ČÕ║öńö©õ║ÄÕģĘõĮōÕ║öńö©ń©ŗÕ║ÅńÜäńē╣Õ«ÜRhealstone |
| Õ║ÅÕÅĘ | Ķ»┤µśÄ |
|---|---|
| ń╝║ńé╣ 1 | µĄŗķćÅńÜ䵜»Õ╣│ÕØ浌ČķŚ┤’╝īĶĆīõĖŹµś»µ£ĆÕØÅÕĆ╝ |
| ń╝║ńé╣ 2 | ÕÉÄńÜäń╗ōĶ«║µś»ÕŖĀµØāÕ╣│ÕØćÕĆ╝’╝īµ▓Īµ£ēń╗ÖÕć║ńĪ«Õ«ÜµØāÕĆ╝ńÜäõŠØµŹ« |
R-RhealstoneµĪåµ×Č
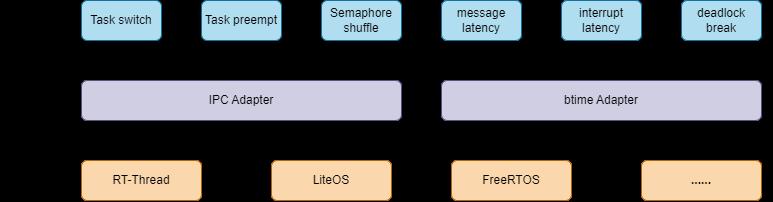
- Ķ«ŠĶ«ĪR-RhealstoneµĪåµ×ČńÜäńø«ńÜä’╝ÜõĖ║õ║åĶāĮĶ«®Õ»╣µ»öńÜäń│╗ń╗¤Õ«×µŚČµĆ¦ńÜ䵥ŗķćÅńÜäõĖĆĶć┤µĆ¦’╝īÕ┐ģķĪ╗õ┐ØĶ»üÕÉīõĖĆõĖ¬ńÄ»Õóā’╝īĶ¦ŻķÖżÕĘ«Õ╝éµĆ¦ÕĖ”µØźµĄŗķćÅÕ╣▓µē░’╝īµēĆõ╗źR-RhealstoneµĪåµ×ȵÅÉõŠøõ║åµōŹõĮ£ń│╗ń╗¤ķĆéķģŹÕ▒é’╝īń╗¤õĖĆķĆéķģŹõĖŹÕÉīµōŹõĮ£ń│╗ń╗¤ńÜäÕÉäõĖ¬µÄźÕÅŻ’╝īńø«ńÜäÕÅ»õ╗źĶŠŠÕł░õĖŖÕ▒éĶ░āńö©Õ▒éµ¼ĪõĖĆĶć┤ŃĆé
õĖŖõĖŗµ¢ćÕłćµŹóµŚČķŚ┤
- õĖŖõĖŗµ¢ćÕłćµŹóµŚČķŚ┤õ╣¤ń¦░õ╗╗ÕŖĪÕłćµŹóµŚČķŚ┤(task switching time)’╝īÕ«Üõ╣ēõĖ║ń│╗ń╗¤Õ£©õĖżõĖ¬ńŗ¼ń½ŗńÜäŃĆüÕżäõ║ÄÕ░▒ń╗¬µĆüÕ╣ČõĖöÕģʵ£ēńøĖÕÉīõ╝śÕģłń║¦ńÜäõ╗╗ÕŖĪõ╣ŗķŚ┤ÕłćµŹóµēĆķ£ĆĶ”üńÜ䵌ČķŚ┤ŃĆéÕ«āÕīģµŗ¼õĖēõĖ¬ķā©Õłå’╝īÕŹ│õ┐ØÕŁśÕĮōÕēŹõ╗╗ÕŖĪõĖŖõĖŗµ¢ćńÜ䵌ČķŚ┤ŃĆüĶ░āÕ║”ń©ŗÕ║ÅķĆēõĖŁµ¢░õ╗╗ÕŖĪńÜ䵌ČķŚ┤ÕÆīµüóÕżŹµ¢░õ╗╗ÕŖĪõĖŖõĖŗµ¢ćńÜ䵌ČķŚ┤ŃĆéÕłćµŹóµēĆķ£ĆńÜ䵌ČķŚ┤õĖ╗Ķ”üÕÅ¢Õå│õ║Äõ┐ØÕŁśõ╗╗ÕŖĪõĖŖõĖŗµ¢ćµēĆńö©ńÜäµĢ░µŹ«ń╗ōµ×äõ╗źÕÅŖµōŹõĮ£ń│╗ń╗¤ķććńö©ńÜäĶ░āÕ║”ń«Śµ│ĢńÜäµĢłńÄćŃĆéõ║¦ńö¤õ╗╗ÕŖĪÕłćµŹóńÜäÕĤÕøĀÕÅ»õ╗źµś»ĶĄäµ║ÉÕŻՊŚ’╝īõ┐ĪÕÅĘķćÅńÜäĶÄĘÕÅ¢ńŁēŃĆéõ╗╗ÕŖĪÕłćµŹóµś»õ╗╗õĖĆÕżÜõ╗╗ÕŖĪń│╗ń╗¤õĖŁÕ¤║µ£¼µĢłńÄćńÜ䵥ŗķćÅńé╣’╝īÕ«āµś»ÕÉīµŁźńÜä’╝īķØ×µŖóÕŹĀńÜä’╝īÕ«×µŚČµÄ¦ÕłČĶĮ»õ╗ČÕ«×ńÄ░õ║åõĖĆń¦ŹÕ¤║õ║ÄÕÉīńŁēõ╝śÕģłń║¦õ╗╗ÕŖĪńÜ䵌ČķŚ┤ńēćĶĮ«ĶĮ¼ń«Śµ│ĢŃĆéÕĮ▒ÕōŹõ╗╗ÕŖĪÕłćµŹóńÜäÕøĀń┤Āµ£ē’╝ÜõĖ╗µ£║CPUńÜäń╗ōµ×ä’╝īµīćõ╗żķøåõ╗źÕÅŖCPUńē╣µĆ¦ŃĆé
- õ╗╗ÕŖĪÕłćµŹóĶ┐ćń©ŗÕó×ÕŖĀõ║åÕ║öńö©ń©ŗÕ║ÅńÜäķóØÕż¢Ķ┤¤ĶŹĘŃĆéCPUńÜäÕåģķā©Õ»äÕŁśÕÖ©ĶČŖÕżÜ’╝īķóØÕż¢Ķ┤¤ĶŹĘÕ░▒ĶČŖķćŹŃĆéõ╗╗ÕŖĪÕłćµŹóµēĆķ£ĆĶ”üńÜ䵌ČķŚ┤ÕÅ¢Õå│õ║ÄCPUµ£ēÕżÜÕ░æÕ»äÕŁśÕÖ©Ķ”üÕģźµĀłŃĆéÕ«×µŚČÕåģµĀĖńÜäµĆ¦ĶāĮõĖŹÕ║öĶ»źõ╗źµ»Åń¦ÆķƤĶāĮÕüÜÕżÜÕ░æµ¼Īõ╗╗ÕŖĪÕłćµŹóµØźĶ»äõ╗Ę’╝īRTOSõĖŁķĆÜÕĖĖµś»1ÕŠ«ń¦ÆÕĘ”ÕÅ│ŃĆé
- ÕĤńÉå’╝ÜÕłøÕ╗║õĖżõĖ¬ÕÉīńŁēõ╝śÕģłń║¦ńÜäõ╗╗ÕŖĪ’╝īõĖżõĖ¬õ╗╗ÕŖĪńøĖõ║ÆÕłćµŹóÕżÜµ¼Ī’╝īµ£ĆÕÉĵ▒éÕ╣│ÕØćÕĆ╝ŃĆé
- µ│©µäÅ’╝ÜŌæĀķ£ĆĶ”üÕćÅÕÄ╗ÕżÜµ¼ĪÕłćµŹóńÜäÕŠ¬ńÄ»µŚČķŚ┤’╝łloop_overhead’╝ē’╝øŌæĪķ£ĆĶ”üÕćÅÕÄ╗õĖ╗ÕŖ©Ķ«®CPUµē¦ĶĪīµŚČķŚ┤’╝łdir_overhead’╝ē
- µŚČķŚ┤Ķ«Īń«ŚÕģ¼Õ╝Å’╝Ü
- total_time’╝ÜÕżÜµ¼ĪõĖŖõĖŗµ¢ćÕłćµŹóµĆ╗µŚČķŚ┤
- loop_overhead’╝ÜÕżÜµ¼ĪÕłćµŹóńÜäÕŠ¬ńÄ»µŚČķŚ┤
- iterations’╝ÜÕłćµŹóńÜäµ¼ĪµĢ░
- dir_overhead’╝ÜĶ░āńö©Ķ«®Õć║CPUµÄźÕÅŻńÜ䵌ČķŚ┤

#include "rst.h"
#include "rst_ipc.h"
#include "rst_btime.h"
static float loop_overhead = 0.0;
static float dir_overhead = 0.0;
static float telapsed = 0.0;
static uint32_t count1, count2;
static rst_task_id rst_task1 = NULL;
static rst_task_id rst_task2 = NULL;
static rst_task_attr rst_task1_attr = {
.name = "task1",
#if RST_BIG_NUM_HIGH_PRIORITY
.priority = RST_TASK_HIGHEST_PRIORITY - 1,
#else
.priority = RST_TASK_HIGHEST_PRIORITY + 1,
#endif
.stack_size = RST_TASK_STACK_SIZE,
};
static rst_task_attr rst_task2_attr = {
.name = "task2",
#if RST_BIG_NUM_HIGH_PRIORITY
.priority = RST_TASK_HIGHEST_PRIORITY - 1,
#else
.priority = RST_TASK_HIGHEST_PRIORITY + 1,
#endif
.stack_size = RST_TASK_STACK_SIZE,
};
static void rst_task2_func(void *arg);
static void rst_task1_func(void *arg)
{
rst_task_create(&rst_task2, rst_task2_func, NULL, &rst_task2_attr);
if(rst_task2 == NULL)
{
RST_LOGE("RST: task2 create failed");
rst_task_delete(NULL);
return;
}
/* Yield processor so second task can startup and run */
rst_task_yield();
for(count1 = 0; count1 < RST_BENCHMARKS_COUNT; count1++)
{
rst_task_yield();
}
rst_task_delete(NULL);
}
static void rst_task2_func(void *arg)
{
/* All overhead accounted for now, we can begin benchmark */
rst_benchmark_time_init();
for(count2 = 0; count2 < RST_BENCHMARKS_COUNT; count2++)
{
rst_task_yield();
}
telapsed = rst_benchmark_time_read();
RST_PRINT_TIME(
"R-Rhealstone: task switch time",
telapsed, /* Total time of all benchmarks */
(RST_BENCHMARKS_COUNT * 2) - 1, /* ( BENCHMARKS * 2 ) - 1 total benchmarks */
loop_overhead, /* Overhead of loop */
dir_overhead /* Overhead of rst_task_yield directive */
);
rst_task_delete(NULL);
}
rst_status rst_task_switch_init(void)
{
/* find overhead of routine (no task switches) */
rst_benchmark_time_init();
for(count1 = 0; count1 < RST_BENCHMARKS_COUNT; count1 ++)
{
}
for(count1 = 0; count1 < RST_BENCHMARKS_COUNT; count1 ++)
{
}
loop_overhead = rst_benchmark_time_read();
/* find overhead of rtems_task_wake_after call (no task switches) */
rst_benchmark_time_init();
rst_task_yield();
dir_overhead = rst_benchmark_time_read();;
rst_task_create(&rst_task1, rst_task1_func, NULL, &rst_task1_attr);
if(rst_task1 == NULL)
{
RST_LOGE("RST: task1 create failed");
return RST_ERROR;
}
return RST_OK;
}
õ╗╗ÕŖĪµŖóÕŹĀµŚČķŚ┤
- µŖóÕŹĀµŚČķŚ┤ÕŹ│ń│╗ń╗¤Õ░åµÄ¦ÕłČµØāõ╗ÄõĮÄõ╝śÕģłń║¦ńÜäõ╗╗ÕŖĪĶĮ¼ń¦╗Õł░ķ½śõ╝śÕģłń║¦õ╗╗ÕŖĪµēĆĶŖ▒Ķ┤╣ńÜ䵌ČķŚ┤ŃĆéõĖ║õ║åÕ»╣õ╗╗ÕŖĪĶ┐øĶĪīµŖóÕŹĀ’╝īń│╗ń╗¤Õ┐ģķĪ╗ķ”¢ÕģłĶ»åÕł½Õ╝ĢĶĄĘķ½śõ╝śÕģłń║¦õ╗╗ÕŖĪÕ░▒ń╗¬ńÜäõ║ŗõ╗Č’╝īµ»öĶŠāõĖżõĖ¬õ╗╗ÕŖĪńÜäõ╝śÕģłń║¦’╝īµ£ĆÕÉÄĶ┐øĶĪīõ╗╗ÕŖĪńÜäÕłćµŹó’╝īµēĆõ╗źµŖóÕŹĀµŚČķŚ┤õĖŁÕīģµŗ¼õ║åõ╗╗ÕŖĪÕłćµŹóµŚČķŚ┤ŃĆé
- Õ«āÕÆīõ╗╗ÕŖĪÕłćµŹóµ£ēõ║øń▒╗õ╝╝’╝īõĮåµś»µŖóÕŹĀµŚČķŚ┤ķĆÜÕĖĖĶŖ▒Ķ┤╣µŚČķŚ┤µø┤ķĢ┐ŃĆéĶ┐Öµś»ÕøĀõĖ║µē¦ĶĪīõĖŁķ”¢ÕģłĶ”üńĪ«Ķ«żÕöżķåÆõ║ŗõ╗Č’╝īÕ╣ČĶ»äõ╝░µŁŻÕ£©Ķ┐ÉĶĪīńÜäõ╗╗ÕŖĪÕÆīĶ»Ęµ▒éĶ┐ÉĶĪīńÜäõ╗╗ÕŖĪńÜäõ╝śÕģłń║¦ķ½śõĮÄ’╝īńäČÕÉĵēŹÕå│իܵś»ÕÉ”ÕłćµŹóõ╗╗ÕŖĪŃĆéÕ«×Ķ┤©õĖŖ’╝īµēƵ£ēńÜäÕżÜÕżäńÉåõ╗╗ÕŖĪÕÅ»õ╗źÕ£©µē¦ĶĪīµ£¤ķŚ┤ÕŖ©µĆüÕłåķģŹõ╝śÕģłń║¦’╝īµēĆõ╗ź’╝īµŖóÕŹĀµŚČķŚ┤õ╣¤µś»ĶĪĪķćÅÕ«×µŚČµĆ¦ĶāĮńÜäķćŹĶ”üµīćµĀćŃĆé
- ÕĤńÉå’╝ÜÕłøÕ╗║õĖżõĖ¬õ╗╗ÕŖĪ’╝īõ╗╗ÕŖĪ1õ╝śÕģłń║¦µ»öõ╗╗ÕŖĪ2õ╝śÕģłń║¦õĮÄ’╝īõĖżõĖ¬õ╗╗ÕŖĪĶ┐øĶĪīµŖóÕŹĀÕżÜµ¼Ī’╝īµ£ĆÕÉĵ▒éÕ╣│ÕØćÕĆ╝ŃĆé
- µ│©µäÅ’╝ÜŌæĀķ£ĆĶ”üÕćÅÕÄ╗ÕżÜµ¼Īõ╗╗ÕŖĪµŖóÕŹĀńÜäÕŠ¬ńÄ»µŚČķŚ┤’╝łloop_overhead’╝ē’╝øŌæĪķ£ĆĶ”üÕćÅÕÄ╗µīéĶĄĘõ╗╗ÕŖĪµēĆķ£ĆĶ”üńÜ䵌ČķŚ┤’╝łdir_overhead’╝ē
- µŚČķŚ┤Ķ«Īń«ŚÕģ¼Õ╝Å’╝Ü
- total_time’╝ÜÕżÜµ¼Īõ╗╗ÕŖĪµŖóÕŹĀµĆ╗µŚČķŚ┤
- loop_overhead’╝ÜÕżÜµ¼Īõ╗╗ÕŖĪµŖóÕŹĀńÜäÕŠ¬ńÄ»µŚČķŚ┤
- iterations’╝Üõ╗╗ÕŖĪµŖóÕŹĀńÜäµ¼ĪµĢ░
- switch_overhead’╝ܵīéĶĄĘõ╗╗ÕŖĪµēĆķ£ĆĶ”üńÜ䵌ČķŚ┤

#include "rst.h"
#include "rst_ipc.h"
#include "rst_btime.h"
static float loop_overhead = 0.0;
static float switch_overhead = 0.0;
static float telapsed = 0.0;
static uint32_t count;
static rst_task_id rst_task1 = NULL;
static rst_task_id rst_task2 = NULL;
static rst_task_attr rst_task1_attr = {
.name = "task1",
#if RST_BIG_NUM_HIGH_PRIORITY
.priority = RST_TASK_HIGHEST_PRIORITY - 3,
#else
.priority = RST_TASK_HIGHEST_PRIORITY + 3,
#endif
.stack_size = RST_TASK_STACK_SIZE,
};
static rst_task_attr rst_task2_attr = {
.name = "task2",
#if RST_BIG_NUM_HIGH_PRIORITY
.priority = RST_TASK_HIGHEST_PRIORITY - 1,
#else
.priority = RST_TASK_HIGHEST_PRIORITY + 1,
#endif
.stack_size = RST_TASK_STACK_SIZE,
};
static void rst_task2_func(void *arg);
static void rst_task1_func(void *arg)
{
/* Start up task2, get preempted */
rst_task_create(&rst_task2, rst_task2_func, NULL, &rst_task2_attr);
if(rst_task2 == NULL)
{
RST_LOGE("RST: task2 create failed");
rst_task_delete(NULL);
return;
}
switch_overhead = rst_benchmark_time_read();
rst_benchmark_time_init();
/* Benchmark code */
for(count = 0; count < RST_BENCHMARKS_COUNT; count++)
{
rst_task_resume(rst_task2); /* Awaken task2, preemption occurs */
}
rst_task_delete(NULL);
}
static void rst_task2_func(void *arg)
{
/* Find overhead of task switch back to task1 (not a preemption) */
rst_benchmark_time_init();
rst_task_suspend(rst_task2);
/* Benchmark code */
for(; count < RST_BENCHMARKS_COUNT - 1;)
{
rst_task_suspend(rst_task2);
}
telapsed = rst_benchmark_time_read();
RST_PRINT_TIME(
"R-Rhealstone: task preempt time",
telapsed, /* Total time of all benchmarks */
RST_BENCHMARKS_COUNT - 1, /* BENCHMARKS - 1 total benchmarks */
loop_overhead, /* Overhead of loop */
switch_overhead /* Overhead of task switch back to task1 */
);
rst_task_delete(NULL);
}
rst_status rst_task_preempt_init(void)
{
/* Find loop overhead */
rst_benchmark_time_init();
for(count = 0; count < ((RST_BENCHMARKS_COUNT * 2) - 1); count++)
{
}
loop_overhead = rst_benchmark_time_read();
rst_task_create(&rst_task1, rst_task1_func, NULL, &rst_task1_attr);
if(rst_task1 == NULL)
{
RST_LOGE("RST: task1 create failed");
return RST_ERROR;
}
return RST_OK;
}
õĖŁµ¢ŁÕ╗ČĶ┐¤µŚČķŚ┤
- õĖŁµ¢ŁÕ╗ČĶ┐¤µŚČķŚ┤µś»µīćõ╗ĵğµöČÕł░õĖŁµ¢Łõ┐ĪÕÅĘÕł░µōŹõĮ£ń│╗ń╗¤ÕüÜÕć║ÕōŹÕ║ö’╝īÕ╣ČÕ«īµłÉĶ┐øÕģźõĖŁµ¢Łµ£ŹÕŖĪõŠŗń©ŗµēĆķ£ĆĶ”üńÜ䵌ČķŚ┤ŃĆéÕżÜõ╗╗ÕŖĪµōŹõĮ£ń│╗ń╗¤õĖŁ’╝īõĖŁµ¢ŁÕżäńÉåķ”¢ÕģłĶ┐øÕģźõĖĆõĖ¬õĖŁµ¢Łµ£ŹÕŖĪńÜäµĆ╗µÄ¦ń©ŗÕ║Å’╝īńäČÕÉĵēŹĶ┐øÕģźķ®▒ÕŖ©ń©ŗÕ║ÅńÜäISRŃĆé
- õĖŁµ¢ŁÕ╗ČĶ┐¤µŚČķŚ┤’╝ص£ĆÕż¦Õģ│õĖŁµ¢ŁµŚČķŚ┤’╝ŗńĪ¼õ╗ČÕ╝ĆÕ¦ŗÕżäńÉåõĖŁµ¢ŁÕł░Õ╝ĆÕ¦ŗµē¦ĶĪīõĖŁµ¢Łµ£ŹÕŖĪõŠŗń©ŗń¼¼õĖƵØĪµīćõ╗żõ╣ŗķŚ┤ńÜ䵌ČķŚ┤ŃĆé
- ńĪ¼õ╗ČÕ╝ĆÕ¦ŗÕżäńÉåõĖŁµ¢ŁÕł░Õ╝ĆÕ¦ŗµē¦ĶĪīõĖŁµ¢Łµ£ŹÕŖĪõŠŗń©ŗńÜäń¼¼õĖƵØĪµīćõ╗żõ╣ŗķŚ┤ńÜ䵌ČķŚ┤ńö▒ńĪ¼õ╗ČÕå│Õ«Ü’╝īµēĆõ╗ź’╝īõĖŁµ¢ŁÕ╗ČĶ┐¤µŚČķŚ┤ńÜäķĢ┐ń¤ŁõĖ╗Ķ”üÕÅ¢Õå│õ║ĵ£ĆÕż¦Õģ│õĖŁµ¢ŁńÜ䵌ČķŚ┤ŃĆéńĪ¼Õ«×µŚČµōŹõĮ£ń│╗ń╗¤ńÜäÕģ│õĖŁµ¢ŁµŚČķŚ┤ķĆÜÕĖĖµś»ÕćĀÕŠ«ń¦Æ’╝īĶĆīLinuxµ£ĆÕØÅÕÅ»ĶŠŠÕćĀµ»½ń¦ÆŃĆé
- ÕĤńÉå’╝ÜÕłøÕ╗║õĖĆõĖ¬õ╗╗ÕŖĪ’╝īõ╗╗ÕŖĪµē¦ĶĪīõĖ╗ÕŖ©Ķ¦”ÕÅæõĖŁµ¢Ł’╝īµē¦ĶĪīÕ«īõĖŁµ¢Łµ£ŹÕŖĪń©ŗÕ║ÅĶ┐öÕø×’╝īń╗¤Ķ«ĪÕģȵŚČķŚ┤ŃĆé
- µ│©µäÅ’╝ÜŌæĀķ£ĆĶ”üÕćÅÕÄ╗Ķ»╗ÕÅ¢µŚČķŚ┤µÄźÕÅŻńÜäĶĆŚµŚČµŚČķŚ┤’╝łtimer_overhead’╝ē’╝ø
- µŚČķŚ┤Ķ«Īń«ŚÕģ¼Õ╝Å’╝Ü
- isr_enter_time’╝ÜÕżÜµ¼Īõ╗╗ÕŖĪµŖóÕŹĀµĆ╗µŚČķŚ┤
- iterations’╝Üõ╗╗ÕŖĪµŖóÕŹĀńÜäµ¼ĪµĢ░
- timer_overhead’╝ÜĶ»╗ÕÅ¢µŚČķŚ┤µÄźÕÅŻńÜäĶĆŚµŚČµŚČķŚ┤

#include "rst.h"
#include "rst_ipc.h"
#include "rst_btime.h"
static float timer_overhead = 0.0;
static float isr_enter_time = 0.0;
static rst_task_id rst_task1 = NULL;
static rst_task_attr rst_task1_attr = {
.name = "task1",
#if RST_BIG_NUM_HIGH_PRIORITY
.priority = RST_TASK_LOWEST_PRIORITY + 1,
#else
.priority = RST_TASK_LOWEST_PRIORITY - 1,
#endif
.stack_size = RST_TASK_STACK_SIZE,
};
static void rst_isr_handler(void *param)
{
isr_enter_time = rst_benchmark_time_read();
}
static void rst_task1_func(void *arg)
{
rst_isr_install(RST_ISR_NUM, rst_isr_handler, NULL);
/* Benchmark code */
rst_benchmark_time_init();
/* goes to Isr_handler */
rst_isr_trigger(RST_ISR_NUM);
RST_PRINT_TIME(
"R-Rhealstone: interrupt latency time",
isr_enter_time,
1, /* Only Rhealstone that isn't an average */
timer_overhead,
0
);
rst_task_delete(NULL);
}
rst_status rst_interrupt_latency_init(void)
{
rst_task_create(&rst_task1, rst_task1_func, NULL, &rst_task1_attr);
if(rst_task1 == NULL)
{
RST_LOGE("RST: task1 create failed");
return RST_ERROR;
}
rst_benchmark_time_init();
rst_benchmark_time_read();
rst_benchmark_time_init();
timer_overhead = rst_benchmark_time_read();
return RST_OK;
}
õ┐ĪÕÅĘķćŵĘʵ┤ŚµŚČķŚ┤
- õ┐ĪÕÅĘķćŵĘʵ┤ŚµŚČķŚ┤(semaphore shuffling time)’╝īµś»µīćõ╗ÄõĖĆõĖ¬õ╗╗ÕŖĪķćŖµöŠõ┐ĪÕÅĘķćÅÕł░ÕÅ”õĖĆõĖ¬ńŁēÕŠģĶ»źõ┐ĪÕÅĘķćÅńÜäõ╗╗ÕŖĪĶó½µ┐Ƶ┤╗ńÜ䵌ČķŚ┤Õ╗ČĶ┐¤ŃĆéÕ£©RTOSõĖŁ’╝īķĆÜÕĖĖµ£ēĶ«ĖÕżÜõ╗╗ÕŖĪÕÉīµŚČń½×õ║ēµ¤ÉõĖĆÕģ▒õ║½ĶĄäµ║É’╝īÕ¤║õ║Äõ┐ĪÕÅĘķćÅńÜäõ║Ƶ¢źĶ«┐ķŚ«õ┐ØĶ»üõ║åõ╗╗õĖƵŚČÕł╗ÕŬµ£ēõĖĆõĖ¬õ╗╗ÕŖĪĶāĮÕż¤Ķ«┐ķŚ«Õģ¼Õģ▒ĶĄäµ║ÉŃĆéõ┐ĪÕÅĘķćŵĘʵ┤ŚµŚČķŚ┤ÕÅŹµśĀõ║åõĖÄõ║Ƶ¢źµ£ēÕģ│ńÜ䵌ČķŚ┤Õ╝ĆķöĆ’╝īÕøĀµŁżõ╣¤µś»ĶĪĪķćÅRTOSÕ«×µŚČµĆ¦ĶāĮńÜäõĖĆõĖ¬ķćŹĶ”üµīćµĀćŃĆé
- ÕĤńÉå’╝ÜÕłøÕ╗║õĖĆõĖ¬õ┐ĪÕÅĘķćÅÕÆīõĖżõĖ¬ńøĖÕÉīõ╝śÕģłń║¦ńÜäõ╗╗ÕŖĪŃĆéõ╗ŻńĀüķ£ĆĶ”üµē¦ĶĪīõĖżµ¼Ī’╝īń¼¼õĖƵ¼Īõ┐ĪÕÅĘķćÅõĖŹõ╗ŗÕģźĶ░āÕ║”’╝īĶ«Īń«Śõ╗╗ÕŖĪÕłćµŹóńÜ䵌ČķŚ┤’╝īń¼¼õ║īµ¼ĪÕżÜµ¼ĪÕŠ¬ńÄ»’╝īõ┐ĪÕÅĘķćÅµÄźÕģźĶ░āÕ║”’╝īõ┐ĪÕÅĘķćÅÕ£©õĖżõĖ¬õ╗╗ÕŖĪõĖŁping-pongµē¦ĶĪī’╝īĶ«Īń«ŚµĆ╗µŚČķŚ┤ŃĆé
- µ│©µäÅ’╝ÜŌæĀķ£ĆĶ”üÕćÅÕÄ╗õ╗╗ÕŖĪÕłćµŹóńÜ䵌ČķŚ┤’╝łswitch_overhead’╝ē’╝ø
- µŚČķŚ┤Ķ«Īń«ŚÕģ¼Õ╝Å’╝Ü
- telapsed’╝ÜÕżÜµ¼Īõ┐ĪÕÅĘķćŵĘʵ┤ŚµĆ╗µŚČķŚ┤
- iterations’╝Üõ┐ĪÕÅĘķćŵĘʵ┤ŚńÜäµ¼ĪµĢ░
- switch_overhead’╝ÜÕłćµŹóńÜ䵌ČķŚ┤

#include "rst.h"
#include "rst_ipc.h"
#include "rst_btime.h"
static float switch_overhead = 0.0;
static float telapsed = 0.0;
static uint32_t count = 0;
static uint32_t sem_exe = 1;
static rst_task_id rst_task1 = NULL;
static rst_task_id rst_task2 = NULL;
static rst_sem_id rst_sem = NULL;
static rst_task_attr rst_task1_attr = {
.name = "task1",
#if RST_BIG_NUM_HIGH_PRIORITY
.priority = RST_TASK_HIGHEST_PRIORITY - 1,
#else
.priority = RST_TASK_HIGHEST_PRIORITY + 1,
#endif
.stack_size = RST_TASK_STACK_SIZE,
};
static rst_task_attr rst_task2_attr = {
.name = "task2",
#if RST_BIG_NUM_HIGH_PRIORITY
.priority = RST_TASK_HIGHEST_PRIORITY - 1,
#else
.priority = RST_TASK_HIGHEST_PRIORITY + 1,
#endif
.stack_size = RST_TASK_STACK_SIZE,
};
static void rst_task2_func(void *arg);
static void rst_task1_func(void *arg)
{
/* Start up task2, yield so it can run */
rst_task_create(&rst_task2, rst_task2_func, NULL, &rst_task2_attr);
if(rst_task2 == NULL)
{
RST_LOGE("RST: task2 create failed");
rst_task_delete(NULL);
return;
}
rst_task_yield();
/* Benchmark code */
for ( ; count < RST_BENCHMARKS_COUNT; ) {
if ( sem_exe == 1 )
{
rst_sem_lock(rst_sem, (rst_time_t)RST_WAIT_FOREVER);
rst_task_yield();
rst_sem_unlock(rst_sem);
rst_task_yield();
}
}
rst_task_delete(NULL);
}
static void rst_task2_func(void *arg)
{
/* Benchmark code */
rst_benchmark_time_init();
for(count = 0; count < RST_BENCHMARKS_COUNT; count++)
{
if(sem_exe == 1)
{
rst_sem_lock(rst_sem, (rst_time_t)RST_WAIT_FOREVER);
rst_task_yield();
rst_sem_unlock(rst_sem);
rst_task_yield();
}
}
telapsed = rst_benchmark_time_read();
if(sem_exe == 0)
{
switch_overhead = telapsed;
}
else
{
RST_PRINT_TIME(
"R-Rhealstone: senaphore shuffle time",
telapsed, /* Total time of all benchmarks */
(RST_BENCHMARKS_COUNT * 2), /* Total number of times deadlock broken*/
switch_overhead, /* Overhead of loop and task switches */
0
);
}
rst_task_delete(NULL);
}
rst_status rst_semaphore_shuffle_init(void)
{
rst_sem = rst_sem_create(1);
if(rst_sem == NULL)
{
RST_LOGE("RST: sem create failed");
return RST_ERROR;
}
__RESTART:
sem_exe = !sem_exe;
/* Get time of benchmark with no semaphore shuffling */
rst_task_create(&rst_task1, rst_task1_func, NULL, &rst_task1_attr);
if(rst_task1 == NULL)
{
RST_LOGE("RST: task1 create failed");
rst_sem_delete(rst_sem);
return RST_ERROR;
}
/* Get time of benchmark with semaphore shuffling */
if(sem_exe == 0)
{
goto __RESTART;
}
return RST_OK;
}
µŁ╗ķöüĶ¦ŻķÖżµŚČķŚ┤
- µŁ╗ķöüĶ¦ŻķÖżµŚČķŚ┤(deadlock breaking time)’╝īÕŹ│ń│╗ń╗¤Ķ¦ŻÕ╝ĆÕżäõ║ĵŁ╗ķöüńŖȵĆüńÜäÕżÜõĖ¬õ╗╗ÕŖĪµēĆķ£ĆĶŖ▒Ķ┤╣ńÜ䵌ČķŚ┤ŃĆ鵣╗ķöüĶ¦ŻķÖżµŚČķŚ┤ÕÅŹµśĀõ║åRTOSĶ¦ŻÕå│µŁ╗ķöüńÜäń«Śµ│ĢńÜäµĢłńÄćŃĆé
- ÕĤńÉå’╝ÜÕłøÕ╗║õĖĆõĖ¬õ┐ĪÕÅĘķćÅÕÆīõĖēõĖ¬õ╗╗ÕŖĪ’╝īõ╝śÕģłń║¦µÄÆÕ║Å’╝Üõ╗╗ÕŖĪ1 < õ╗╗ÕŖĪ2 < õ╗╗ÕŖĪ3ŃĆéõ╗ŻńĀüķ£ĆĶ”üµē¦ĶĪīõĖżµ¼Ī’╝īń¼¼õĖƵ¼Īõ┐ĪÕÅĘķćÅõĖŹõ╗ŗÕģźĶ░āÕ║”’╝īĶ«Īń«Śõ╗╗ÕŖĪ3ÕłćµŹóÕł░õ╗╗ÕŖĪ2’╝īõ╗╗ÕŖĪ2ÕłćµŹóÕł░õ╗╗ÕŖĪ1ÕŠŚµŚČķŚ┤’╝łÕŹ│õ╗Äķ½śõ╝śÕģłń║¦ÕłćµŹóÕł░õĮÄõ╝śÕģłń║¦ÕŠŚµŚČķŚ┤’╝ē’╝īń¼¼õ║īµ¼ĪÕżÜµ¼ĪÕŠ¬ńÄ»’╝īõ┐ĪÕÅĘķćÅµÄźÕģźĶ░āÕ║”’╝īõ╗╗ÕŖĪ3µŁ╗ķöü’╝īõ╗╗ÕŖĪ2ÕöżķåÆõ╗╗ÕŖĪ1’╝īõ╗╗ÕŖĪ1Ķ¦ŻķÖżµŁ╗ķöü’╝īķĆÜĶ┐ćń╗¤Ķ«ĪÕżÜµ¼Ī’╝īµ▒éÕ╣│ÕØćÕĆ╝ŃĆé
- µ│©µäÅ’╝ÜŌæĀķ£ĆĶ”üÕćÅÕÄ╗õ╗╗ÕŖĪÕłćµŹóńÜ䵌ČķŚ┤’╝łswitch_overhead’╝ē’╝ø
- µŚČķŚ┤Ķ«Īń«ŚÕģ¼Õ╝Å’╝Ü
- telapsed’╝ÜÕżÜµ¼ĪµŁ╗ķöüĶ¦ŻķÖżµĆ╗µŚČķŚ┤
- iterations’╝ܵŁ╗ķöüĶ¦ŻķÖżńÜäµ¼ĪµĢ░
- switch_overhead’╝Üõ╗╗ÕŖĪÕłćµŹóńÜ䵌ČķŚ┤
- lock_overhead’╝ÜĶ░āńö©õ┐ĪÕÅĘķćŵīüµ£ēµÄźÕÅŻµēĆķ£ĆĶ”üÕŠŚµŚČķŚ┤

#include "rst.h"
#include "rst_ipc.h"
#include "rst_btime.h"
static float switch_overhead = 0.0;
static float lock_overhead = 0.0;
static float telapsed = 0.0;
static uint32_t count = 0;
static uint32_t sem_exe = 1;
static rst_task_id rst_task1 = NULL;
static rst_task_id rst_task2 = NULL;
static rst_task_id rst_task3 = NULL;
static rst_sem_id rst_sem = NULL;
static rst_task_attr rst_task1_attr = {
.name = "task1",
#if RST_BIG_NUM_HIGH_PRIORITY
.priority = RST_TASK_HIGHEST_PRIORITY - 1,
#else
.priority = RST_TASK_HIGHEST_PRIORITY + 1,
#endif
.stack_size = RST_TASK_STACK_SIZE,
};
static rst_task_attr rst_task2_attr = {
.name = "task2",
#if RST_BIG_NUM_HIGH_PRIORITY
.priority = RST_TASK_HIGHEST_PRIORITY - 3,
#else
.priority = RST_TASK_HIGHEST_PRIORITY + 3,
#endif
.stack_size = RST_TASK_STACK_SIZE,
};
static rst_task_attr rst_task3_attr = {
.name = "task3",
#if RST_BIG_NUM_HIGH_PRIORITY
.priority = RST_TASK_HIGHEST_PRIORITY - 5,
#else
.priority = RST_TASK_HIGHEST_PRIORITY + 5,
#endif
.stack_size = RST_TASK_STACK_SIZE,
};
static void rst_task1_func(void *arg)
{
/* All tasks have had time to start up once TA01 is running */
/* Benchmark code */
rst_benchmark_time_init();
for(count = 0; count < RST_BENCHMARKS_COUNT; count++)
{
if(sem_exe == 1)
{
/* Block on call */
rst_sem_lock(rst_sem, (rst_time_t)RST_WAIT_FOREVER);
/* Release semaphore immediately after obtaining it */
rst_sem_unlock(rst_sem);
}
/* Suspend self, go to task2 */
rst_task_suspend(rst_task1);
}
telapsed = rst_benchmark_time_read();
if(sem_exe == 0)
{
switch_overhead = telapsed;
}
else
{
RST_PRINT_TIME(
"R-Rhealstone: deadlock break time",
telapsed, /* Total time of all benchmarks */
RST_BENCHMARKS_COUNT, /* Total number of times deadlock broken*/
switch_overhead, /* Overhead of loop and task switches */
lock_overhead
);
}
rst_task_delete(NULL);
}
static void rst_task2_func(void *arg)
{
/* Start up task1, get preempted */
rst_task_create(&rst_task1, rst_task1_func, NULL, &rst_task1_attr);
if(rst_task1 == NULL)
{
RST_LOGE("RST: task1 create failed");
rst_task_delete(NULL);
return;
}
/* Benchmark code */
for( ; count < RST_BENCHMARKS_COUNT; )
{
/* Suspend self, go to task1 */
rst_task_suspend(rst_task2);
/* Wake up task1, get preempted */
rst_task_resume(rst_task1);
}
rst_task_delete(NULL);
}
static void rst_task3_func(void *arg)
{
if(sem_exe == 1)
{
/* Low priority task holds mutex */
rst_sem_lock(rst_sem, (rst_time_t)RST_WAIT_FOREVER);
}
/* Start up task2, get preempted */
rst_task_create(&rst_task2, rst_task2_func, NULL, &rst_task2_attr);
if(rst_task2 == NULL)
{
RST_LOGE("RST: task2 create failed");
rst_task_delete(NULL);
return;
}
for( ; count < RST_BENCHMARKS_COUNT; )
{
if(sem_exe == 1)
{
/* Preempted by task1 upon release */
rst_sem_unlock(rst_sem);
/* Prepare for next Benchmark */
rst_sem_lock(rst_sem, (rst_time_t)RST_WAIT_FOREVER);
}
/* Wake up task2, get preempted */
rst_task_resume(rst_task2);
}
rst_task_delete(NULL);
}
rst_status rst_deadlock_break_init(void)
{
rst_sem = rst_sem_create(1);
if(rst_sem == NULL)
{
RST_LOGE("RST: sem create failed");
return RST_ERROR;
}
/* find overhead of obtaining semaphore */
rst_benchmark_time_init();
rst_sem_lock(rst_sem, (rst_time_t)RST_WAIT_FOREVER);
lock_overhead = rst_benchmark_time_read();
rst_sem_unlock(rst_sem);
__RESTART:
sem_exe = !sem_exe;
/* Get time of benchmark with no semaphores involved, i.e. find overhead */
rst_task_create(&rst_task3, rst_task3_func, NULL, &rst_task3_attr);
if(rst_task3 == NULL)
{
RST_LOGE("RST: task3 create failed");
rst_sem_delete(rst_sem);
return RST_ERROR;
}
/* Get time of benchmark with semaphores */
if(sem_exe == 0)
{
goto __RESTART;
}
rst_sem_delete(rst_sem);
return RST_OK;
}
õ┐Īµü»õ╝ĀĶŠōÕ╗ČĶ┐¤
- õ┐Īµü»õ╝ĀĶŠōÕ╗ČĶ┐¤(datagram throuShput time)’╝īµīćõĖĆõĖ¬õ╗╗ÕŖĪķĆÜĶ┐ćĶ░āńö©RTOSńÜäµČłµü»ķś¤ÕłŚ’╝īµŖŖµĢ░µŹ«õ╝ĀķĆüÕł░ÕÅ”õĖĆõĖ¬õ╗╗ÕŖĪÕÄ╗µŚČ’╝īµ»Åń¦ÆÕÅ»õ╗źõ╝ĀķĆüńÜäÕŁŚĶŖéµĢ░ŃĆé
- ÕĤńÉå’╝ÜÕłøÕ╗║õĖĆõĖ¬µČłµü»ķś¤ÕłŚÕÆīõĖżõĖ¬õ╗╗ÕŖĪ’╝īõ╝śÕģłń║¦µÄÆÕ║Å’╝Üõ╗╗ÕŖĪ1 < õ╗╗ÕŖĪ2ŃĆéõ╗╗ÕŖĪ1Ķ┤¤Ķ┤ŻÕÅæķĆüµĢ░µŹ«’╝īõ╗╗ÕŖĪ2Ķ┤¤Ķ┤ŻµÄźµöȵĢ░µŹ«’╝īµē¦ĶĪīÕżÜµ¼Ī’╝īµ▒éÕ╣│ÕØćÕĆ╝
- µ│©µäÅ’╝ÜŌæĀķ£ĆĶ”üÕćÅÕÄ╗Ķ░āńö©µČłµü»ķś¤ÕłŚµÄźµöČÕćĮµĢ░ńÜ䵌ČķŚ┤’╝łreceive_overhead’╝ē’╝ø
- µŚČķŚ┤Ķ«Īń«ŚÕģ¼Õ╝Å’╝Ü
- telapsed’╝ÜÕżÜµ¼Īõ┐Īµü»õ╝ĀĶŠōµĆ╗µŚČķŚ┤
- iterations’╝ܵŁ╗ķöüĶ¦ŻķÖżńÜäµ¼ĪµĢ░
- loop_overhead’╝ÜÕżÜµ¼ĪÕŠ¬ńÄ»ńÜ䵌ČķŚ┤
- receive_overhead’╝ÜĶ░āńö©µČłµü»ķś¤ÕłŚµÄźµöČÕćĮµĢ░ńÜ䵌ČķŚ┤

#include "rst.h"
#include "rst_ipc.h"
#include "rst_btime.h"
#define RST_QUEUE_BUFF_SIZE 4
static float loop_overhead = 0.0;
static float receive_overhead = 0.0;
static float telapsed = 0.0;
static uint32_t count;
static rst_task_id rst_task1 = NULL;
static rst_task_id rst_task2 = NULL;
static rst_queue_id rst_queue = NULL;
static int queue_buff[RST_QUEUE_BUFF_SIZE] = {0};
static rst_task_attr rst_task1_attr = {
.name = "task1",
#if RST_BIG_NUM_HIGH_PRIORITY
.priority = RST_TASK_HIGHEST_PRIORITY - 3,
#else
.priority = RST_TASK_HIGHEST_PRIORITY + 3,
#endif
.stack_size = RST_TASK_STACK_SIZE,
};
static rst_task_attr rst_task2_attr = {
.name = "task2",
#if RST_BIG_NUM_HIGH_PRIORITY
.priority = RST_TASK_HIGHEST_PRIORITY - 1,
#else
.priority = RST_TASK_HIGHEST_PRIORITY + 1,
#endif
.stack_size = RST_TASK_STACK_SIZE,
};
static void rst_task2_func(void *arg);
static void rst_task1_func(void *arg)
{
/* Put a message in the queue so recieve overhead can be found. */
rst_queue_send(rst_queue,
(const void *)queue_buff,
(uint32_t)sizeof(queue_buff),
(rst_time_t)RST_WAIT_FOREVER);
/* Start up second task, get preempted */
rst_task_create(&rst_task2, rst_task2_func, NULL, &rst_task2_attr);
if(rst_task2 == NULL)
{
RST_LOGE("RST: task2 create failed");
rst_task_delete(NULL);
return;
}
for(; count < RST_BENCHMARKS_COUNT; count++)
{
rst_queue_send(rst_queue,
(const void *)queue_buff,
(uint32_t)sizeof(queue_buff),
(rst_time_t)RST_WAIT_FOREVER);
}
rst_task_delete(NULL);
}
static void rst_task2_func(void *arg)
{
/* find recieve overhead - no preempt or task switch */
rst_benchmark_time_init();
rst_queue_recv(rst_queue, (void *)queue_buff,
(uint32_t)sizeof(queue_buff));
receive_overhead = rst_benchmark_time_read();
/* Benchmark code */
rst_benchmark_time_init();
for(count = 0; count < RST_BENCHMARKS_COUNT - 1; count++)
{
rst_queue_recv(rst_queue, (void *)queue_buff,
(uint32_t)sizeof(queue_buff));
}
telapsed = rst_benchmark_time_read();
RST_PRINT_TIME(
"R-Rhealstone: message latency time",
telapsed, /* Total time of all benchmarks */
RST_BENCHMARKS_COUNT - 1, /* BENCHMARKS - 1 total benchmarks */
loop_overhead, /* Overhead of loop */
receive_overhead /* Overhead of recieve call and task switch */
);
rst_task_delete(NULL);
}
rst_status rst_message_latency_init(void)
{
rst_queue = rst_queue_create(sizeof(queue_buff), 1);
if(rst_queue == NULL)
{
RST_LOGE("RST: queue create failed");
return RST_ERROR;
}
rst_benchmark_time_init();
for(count = 0; count < (RST_BENCHMARKS_COUNT - 1); count++)
{
}
loop_overhead = rst_benchmark_time_read();
rst_task_create(&rst_task1, rst_task1_func, NULL, &rst_task1_attr);
if(rst_task1 == NULL)
{
RST_LOGE("RST: task1 create failed");
rst_queue_delete(rst_queue);
return RST_ERROR;
}
return RST_OK;
}
RTOSÕ»╣µ»öń╗ōĶ«║
Õ»╣µ»öńÄ»ÕóāĶ»┤µśÄ
| ķĪ╣ | Ķ»┤µśÄ |
|---|---|
| ĶŖ»ńēć | ĶŖ»ńēćÕ×ŗÕÅĘ’╝Üstm32f401 ĶŖ»ńēćµ×ȵ×ä’╝ÜCortex-M4 õĖ╗ķóæ’╝Ü84 MHz |
| Õ╝ĆÕÅæńÄ»Õóā | KEIL 5.x |
| ÕĘźÕģĘķōŠ | ARMCC |
Õ»╣µ»öń╗ōµ×£Ķ»┤µśÄ
| Õ»╣µ»öķĪ╣ | RT-Thread | LiteOS | FreeRTOS | TobudOS |
|---|---|---|---|---|
| õĖŖõĖŗµ¢ćÕłćµŹó | 2.594596 us | 6.739740 us | 1.049049 us | 2.343343 |
| õ╗╗ÕŖĪµŖóÕŹĀ | 7.360721 us | 7.603206 us | 2.715431 us | 4.523046 us |
| õĖŁµ¢ŁÕ╗ČĶ┐¤ | 2.000000 us | 1.000000 us | 1.000000 us | 1.000000 us |
| õ┐ĪÕÅĘķćŵĘʵ┤Ś | 23.829000 us | 25.588000 us | 19.496000 us | 18.451000 us |
| µŁ╗ķöüĶ¦ŻķÖż | 18.108000 us | 18.074000 us | 21.522000 us | 31.606000 us |
| õ┐Īµü»õ╝ĀĶŠōÕ╗ČĶ┐¤ | 7.749499 us | 7.390782 us | 7.298597 us | 3.446894 us |
µĆ╗ń╗ō
Õ╝Ƶ║ÉķōŠµÄź
ķōŠµÄźĶĘ»ÕŠä’╝Ühttps://github.com/RiceChen0/r-rhealstone.git
Ķ»┤µśÄ’╝ÜĶ»źµĪåµ×Čńø«ÕēŹÕĘ▓ń╗ÅķĆéķģŹõĮ£õĖ║RT-ThreadńÜäĶĮ»õ╗ČÕīģ’╝īÕÅ»õ╗źķĆÜĶ┐ćĶĮ»õ╗ČÕīģõĮōķ¬īÕģČÕŖ¤ĶāĮ
