وœ€è؟‘ه‡ ن¸ھClassic AUTOSARé،¹ç›®ه¹¶è،Œهœ¨هپڑ,و— è®؛وˆ‘و€ژن¹ˆهˆ‡و¥هˆ‡هژ»ï¼Œو€ژن¹ˆه¥½هƒڈو¯ڈن¸ھé،¹ç›®éƒ½وک¯S32Gه•ٹï¼پوˆ‘都ه؟«ن¸چ认识هˆ«çڑ„èٹ¯ç‰‡ن؛†....

ه¥½هگ§â•®(╯-â•°)â•ï¼Œç»•ن¸چه¼€ه°±ç»•ن¸چه¼€ï¼Œè°پهڈ«S32Gè؟™ن¹ˆçپ«ه‘¢---- ه…³é”®وک¯و‰“ه·¥ن؛؛ن¹ںو²،ه¾—选ن¸چوک¯ï¼Œه’±ن¸چ能وŒ‘م€‚
ن½†وک¯هگ§ï¼Œهœ¨S32Gن¸ٹ调试çڑ„ن»£ç پè¶ٹو¥è¶ٹه¤ڑن¹‹هگژ,ن»£ç پè·‘ç€è·‘ç€è؟›ه…¥ه¼‚ه¸¸çڑ„وƒ…ه†µن¹ںéه¸¸ه¤ڑ(ن¼¼ن¹ژوڑ´éœ²ن؛†وˆ‘çڑ„编程و°´ه¹³ï¼ںï¼ں),调试è؟‡هµŒه…¥ه¼ڈçڑ„都و‡‚,ن¸€و—¦è؟›ه…¥é”™è¯¯وˆ–者ه¼‚ه¸¸ï¼Œه¾€ه¾€è¦پé¢ه¯¹ن¸€ه †ه¼‚ه¸¸ه¤„çگ†ه‡½و•°ï¼Œè€Œن¸”è؟کوک¯و±‡ç¼–ï¼پ虽说ه’±ن¹ںن¸چوک¯ن¸چو‡‚و±‡ç¼–,ن½†وک¯è°ƒèµ·و¥è‚¯ه®ڑن¸چه¦‚调试Cن»£ç پ直观م€‚
é‚£ن¹ˆé—®é¢کو¥ن؛†ï¼Œو€ژن¹ˆèƒ½ه¤ںه؟«é€ں解ه†³è؟™ن¸ھé—®é¢که‘¢ï¼Œه¯¹هگ§ï¼ںçژ°هœ¨ن¹ںن¸چçں¥éپ“وک¯و€ژن¹ˆن؛†ï¼ŒهµŒه…¥ه¼ڈ软ن»¶ن¹ںه¼€ه§‹وگو•ڈوچ·ه¼€هڈ‘,ن¸¤ه‘¨ن¸€ن¸ھsprint(و²،وœ‰è¯´و•ڈوچ·ه¼€هڈ‘ن¸چه¯¹çڑ„و„ڈو€ï¼Œو ه°±وک¯ن½ ه¯¹ï¼‰ï¼Œè€پوœ‰ن؛؛ه‚¬وˆ‘ه•ٹï¼پن¸چن؟،看看وˆ‘çڑ„è؛«هگژ,Scrum Master,é،¹ç›®ç»ڈçگ†ï¼Œè؟کوœ‰ه®¢وˆ·çˆ¸çˆ¸ن¸€ç›´ه“”ه“”هڈ¨هڈ¨çڑ„,烦çڑ„3و¬،ه¹‚ï¼پ

è؟™ن¸ھو—¶ه€™ç‰¢è®°و›¼èپ”è€په¤§ه“¥C罗,ه•ٹن¸چ,Bè´¹çڑ„“هˆ«و…Œï¼Œه†·é™â€ï¼پوˆ‘ن»¬ن¸چè¦پو€•é—®é¢ک,وƒ³وƒ³هڈ¯ن»¥و€ژن¹ˆè§£ه†³ه®ƒم€‚
请ن½ çژ°هœ¨ه›ç”وˆ‘ه‡ ن¸ھé—®é¢کï¼ڑ
S32Gوک¯ن»€ن¹ˆه…¬هڈ¸çڑ„èٹ¯ç‰‡ï¼ں
NXPï¼پ(هڈ¯ن»¥ç»™وˆ‘و‰“点ه¹؟ه‘ٹè´¹هگ—ï¼ںï¼ں)
S32G适用هœ؛و™¯وک¯ن»€ن¹ˆï¼ں
网ه…³ï¼پ(çژ°هœ¨وˆ‘ه؟«ç½‘ه…³PTSDن؛†م€‚م€‚م€‚)
S32Gوک¯هں؛ن؛ژن»€ن¹ˆو¶و„çڑ„ï¼ں
Cortex-M7ï¼پ
OK,è؟™ن¸ھن¸‰è؟ه›ç”çڑ„éه¸¸ه¥½ï¼Œو—¢ç„¶çں¥éپ“ه®ƒوک¯Cortex-M7و¶و„çڑ„,那ن¹ˆه°±ه¥½هٹن؛†م€‚
ن»€ن¹ˆï¼ŒCortex-Mوک¯ن»€ن¹ˆï¼ںوˆ‘ç»™ن½ وŒ‡ن¸ھè·¯ï¼ڑArm Product Filter – Armآ®

Cortex-Mè؟کهˆ†ن؛†ه¾ˆه¤ڑç³»هˆ—,ه…¶ن»–وˆ‘ن»¬وڑ‚ن¸”ن¸چè،¨ï¼Œن¸»è¦پè؟کوک¯ه…ˆو¥ن؛†è§£ن¸‹S32Gه¯¹ه؛”çڑ„M7م€‚

ن¸€èˆ¬و¥è¯´ï¼Œèٹ¯ç‰‡وک¯وœ‰ç›¸ه؛”çڑ„ه¯„هکه™¨و¥ه‘ٹ诉وˆ‘ن»¬هڈ‘ç”ںن؛†ن»€ن¹ˆو ·çڑ„ه¼‚ه¸¸/错误,ه¯¹ن؛ژCortex-M,وœ‰ن»€ن¹ˆه¯„هکه™¨هڈ¯ن»¥وڈگن¾›è؟™ن؛›ن؟،وپ¯ه‘¢ï¼ں
ن»ژ第ن¸€و¥هˆ†وگçڑ„角ه؛¦و¥è¯´ï¼Œç›¸ه…³çڑ„ه¯„هکه™¨وœ‰ن¸¤ن¸ھ,Configurable Fault Status Register(CSFR)ه’ŒHardFault Status Register(HFSR)م€‚
هڈ¯é…چç½®و•…éڑœçٹ¶و€په¯„هکه™¨ Configurable Fault Status Registers (CFSR)
è؟™ن¸€ن¸ھ32ن½چه¯„هکه™¨هŒ…هگ«ن؛†ن½•ç§چو•…éڑœه¯¼è‡´è؟›ه…¥ه¼‚ه¸¸çڑ„ن؟،وپ¯ï¼Œن¸€ه…±ه’Œن¸‰ç§چçٹ¶و€پوœ‰ه…³ï¼ڑ

UFSR - UsageFault Status Register
BFSR - BusFault Status Register
MMFSR - MemManage Status Register
ن½؟用و•…éڑœçٹ¶و€په¯„هکه™¨ UsageFault Status Register (UFSR)
UFSRهچ 2ن¸ھه—èٹ‚é•؟ه؛¦ï¼Œن»£è،¨ه’Œه†…هکè®؟é—®و— ه…³çڑ„و•…éڑœï¼Œن¾‹ه¦‚ه°è¯•و‰§è،Œéو³•وŒ‡ن»¤ ,وˆ–者ه°è¯•è؟›ه…¥éو³•çٹ¶و€پم€‚
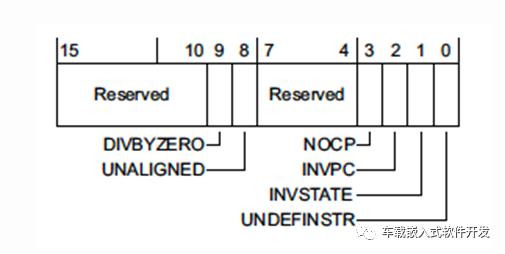
DIVBYZERO - هڈ‘ç”ںن؛†é™¤é›¶و“چن½œم€‚هڈ¯é€ڑè؟‡CCRه¯„هکه™¨é…چç½®وک¯هگ¦ه¼€هگ¯و¤و•…éڑœو£€وµ‹م€‚
UNALIGNED - هڈ‘ç”ںن؛†وœھه¯¹ه…¶هœ°ه€è®؟é—®و“چن½œï¼Œن¾‹ه¦‚è®؟é—®ن؛†ن¸€ن¸ھو²،وœ‰8ه—èٹ‚ه¯¹é½گçڑ„uint64_tç±»ه‹هڈکé‡ڈم€‚ه¯¹ن؛ژ4ه—èٹ‚هڈٹن»¥ن¸‹çڑ„éه¯¹ه…¶هœ°ه€è®؟问,ن¹ںهڈ¯ن»¥é€ڑè؟‡CCRه¯„هکه™¨é…چç½®وک¯هگ¦ه¼€هگ¯و£€وµ‹م€‚
NOCP - هœ¨هچڈه¤„çگ†ه™¨ن¸چهکهœ¨وˆ–者وœھن½؟能çڑ„وƒ…ه†µن¸‹ï¼Œو‰§è،Œن؛†Cortex-Mهچڈه¤„çگ†ه™¨وŒ‡ن»¤م€‚ن¸€ن¸ھو™®éپچçڑ„هœ؛و™¯وک¯هœ¨ç¼–译选é،¹ه½“ن¸ن½؟用-mfloat-abi=hard-mfpu=fpv4-sp-d16è؟›è،Œوµ®ç‚¹و“چن½œï¼Œن½†هœ¨ç¨‹ه؛ڈهگ¯هٹ¨/و‰§è،Œو—¶ه¹¶وœھن½؟能هچڈه¤„çگ†ه™¨م€‚
INVPC - EXC_RETURNن¸€è‡´و€§و£€وں¥é”™è¯¯م€‚
INVSTATE - ه¤„çگ†ه™¨ه°è¯•ن½؟用éو³•çڑ„Execution Program Status Register (EPSR) ه€¼و‰§è،ŒوŒ‡ن»¤م€‚ESPRه¯„هکه™¨è؟½è¸ھه¤„çگ†ه™¨وک¯هگ¦هœ¨thumbçٹ¶و€پم€‚ه†™و±‡ç¼–ن»£ç پو—¶ه®¹وک“وœ‰è؟™ç§چ错误م€‚
UNDEFINSTR - و‰§è،Œن؛†وœھه®ڑن¹‰وŒ‡ن»¤ï¼Œه¦‚وœهœ¨ه¼‚ه¸¸ه¤„çگ†وژ¨ه‡؛و—¶و ˆوچںهڈ,ن¼ڑ触هڈ‘è؟™ن¸ھه¼‚ه¸¸م€‚وˆ–者,ن»£ç پè·¯ه¾„ه؛”该و— و³•è®؟é—®هˆ°çڑ„و—¶ه€™ï¼Œç¼–译ه™¨ن¹ںهڈ¯èƒ½ن¼ڑç”ںوˆگوœھه®ڑن¹‰وŒ‡ن»¤م€‚
و€»ç؛؟و•…éڑœçٹ¶و€په¯„هکه™¨ BusFault Status Register (BFSR)
BFSRهچ 1ن¸ھه—èٹ‚é•؟ه؛¦ï¼Œن»£è،¨é¢„هڈ–وŒ‡ن»¤وˆ–者ه†…هکè®؟问错误م€‚
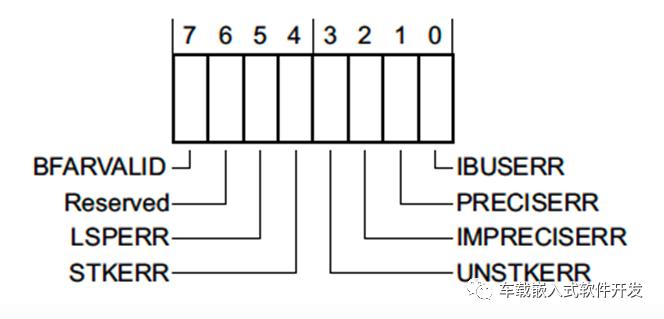
BFARVALID - ن»£è،¨ن½چن؛ژ0xE000ED38هœ°ه€çڑ„32ن½چه¯„هکه™¨Bus Fault Address Register (BFAR), هکه‚¨ن؛†è§¦هڈ‘è؟™ن¸ھو•…éڑœçڑ„هœ°ه€م€‚
LSPERR & STKERR - floating-point lazy state错误وˆ–者ه¼‚ه¸¸ه…¥هڈ£و—¶stack错误
UNSTKERR - ن»ژه¼‚ه¸¸è؟”ه›و—¶هڈ‘ç”ںو•…éڑœï¼Œو¯”ه¦‚ه¼‚ه¸¸ه¤„çگ†و—¶و ˆوچںهڈ,وˆ–者SPوŒ‡é’ˆè¢«و”¹هڈک而ه†…ه®¹و²،وœ‰è¢«و£ç،®هˆه§‹هŒ–م€‚
IMPRECISERR - ç،¬ن»¶وک¯هگ¦هڈ¯ن»¥ه†³ه®ڑو•…éڑœçڑ„ç،®هˆ‡ن½چç½®م€‚
PRECISERR - وک¯هگ¦è؟›ه…¥ه¼‚ه¸¸ه‰چçڑ„وŒ‡ن»¤ه¯¼è‡´é”™è¯¯
IMPRECISERRه¯¹ن؛ژ调试bus erroréه¸¸é‡چè¦پ,و¯•ç«ںه®ƒن»£è،¨ن؛†وˆ‘ن»¬وک¯هگ¦èƒ½ه¤ںç›´وژ¥èژ·هڈ–ه¯¼è‡´ه¼‚ه¸¸çڑ„وŒ‡ن»¤هœ¨ن½•ه¤„م€‚وŒ‡ن»¤èژ·هڈ–ه’Œو•°وچ®è½½ه…¥ï¼Œهœ¨Cortex-M设ه¤‡ن¸ٹو€»وک¯ن¼ڑن؛§ç”ںهگŒو¥و•…éڑœï¼Œè€Œهکه‚¨و“چن½œهˆ™هڈ¯èƒ½ن؛§ç”ںه¼‚و¥و•…éڑœï¼Œه› ن¸؛وœ‰çڑ„و—¶ه€™ه†™ه…¥و•°وچ®ن¼ڑه…ˆè¢«ç¼“هکèµ·و¥ï¼Œç„¶هگژو‰چن¼ڑه†™è؟›و•°وچ®ï¼Œن»¥éپ؟ه…چوµپو°´ç؛؟هپœç•™ï¼Œو‰€ن»¥PCوŒ‡é’ˆه…ˆن؛ژو•°وچ®هکه‚¨ه®Œو¯•ن¹‹ه‰چ移هٹ¨ï¼Œو‰§è،Œه…¶ن»–وŒ‡ن»¤م€‚
و‰€ن»¥ï¼Œه½“ه‡؛çژ°imprecise bus errorو—¶ï¼Œن½ هڈ¯èƒ½éœ€è¦پهœ¨وٹ¥ه‘ٹçڑ„و•…éڑœهœ°ه€é™„è؟‘看看وک¯هگ¦وœ‰هڈ¯èƒ½ه¯¼è‡´ه¼‚ه¸¸çڑ„هکه‚¨و“چن½œم€‚ه¦‚وœMCUو”¯وŒپARMçڑ„Embedded Trace Macrocell(ETM),那ن¹ˆن¹ںهڈ¯ن»¥é€ڑè؟‡è°ƒè¯•ه™¨وں¥çœ‹وœ€è؟‘被و‰§è،Œçڑ„وŒ‡ن»¤هژ†هڈ²م€‚
Auxiliary Bus Fault Status Register (ABFSR)
ه½“IMPRECISE errorهڈ‘ç”ںو—¶ï¼Œوˆ‘ن»¬هڈ¯ن»¥هˆ©ç”¨ن»…هœ¨Cortex-M7设ه¤‡ن¸ٹو‰چوœ‰çڑ„ABFSRه¯„هکه™¨ï¼Œوں¥çœ‹ن½•ç§چه†…هکو€»ç؛؟ن؛§ç”ںçڑ„و•…éڑœم€‚
è؟™é‡Œçڑ„AXIM,EPPB,AHBP,DTCM,ITCM都وک¯وژ¥هڈ£ç±»ه‹ï¼Œè؟™é‡Œن¸چه†چهپڑه±•ه¼€م€‚
ه†…هکو•…éڑœه¯„هکه™¨MemManage Status Register (MMFSR)
MMFSRوٹ¥ه‘ٹه†…هکن؟وٹ¤هچ•ه…ƒو•…éڑœم€‚
ن¸€èˆ¬هœ°ï¼ŒMPUو•…éڑœهڈھهœ¨MPUé…چç½®ه¹¶ن½؟能çڑ„وƒ…ه†µن¸‹و‰چهڈ¯èƒ½ن¼ڑ被触هڈ‘,然而,ن¾‹ه¦‚ه°è¯•هœ¨ç³»ç»ںهœ°ه€çڑ„范ه›´و‰§è،Œن»£ç پç‰وƒ…ه†µن¸‹ï¼Œن¹ںن¼ڑ触هڈ‘ه†…هکè®؟问错误م€‚
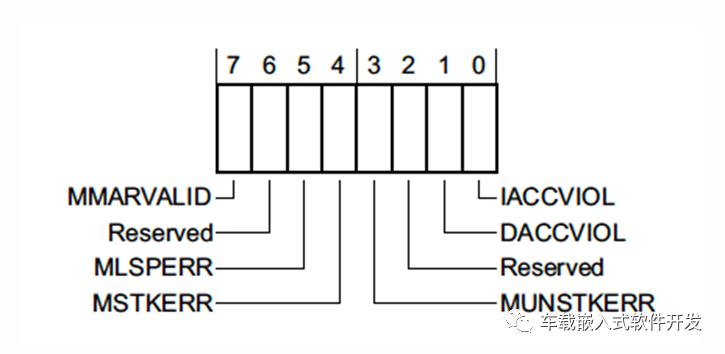
MMARVALID - 32ن½چه¯„هکه™¨MemManage Fault Address Register (MMFAR)وک¯هگ¦وœ‰و•ˆن؟هکن؛†وœںوœ›è®؟é—®çڑ„ه†…هکهœ°ه€
MLSPERR & MSTKERR - ه…¸ه‹çڑ„错误وک¯ï¼ŒMPU用و¥و£€وµ‹و ˆو؛¢ه‡؛و—¶ï¼Œlazy state preservationوˆ–exception entryو—¶çڑ„و•…éڑœ
MUNSTKERR - ن»ژه¼‚ه¸¸è؟”ه›و—¶هڈ‘ç”ںçڑ„و•…éڑœ
DACCVIOL - و•°وچ®è®؟é—®ه¯¼è‡´çڑ„错误
IACCVIOL - وŒ‡ن»¤و‰§è،Œه¯¼è‡´çڑ„MPUوˆ–Execute Never (XN) و•…éڑœï¼ˆ0xE0000000هڈٹو›´é«کçڑ„هœ°ه€وک¯و— و³•è¢«و‰§è،Œçڑ„)
HardFault Status Register (HFSR)
HFSRه¯„هکه™¨ه¸¦وœ‰ه¯¼è‡´HardFaultçڑ„هژںه› ن؟،وپ¯م€‚
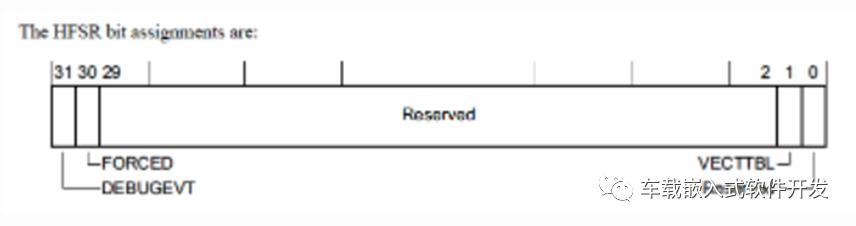
DEBUGEVT - debugهگç³»ç»ںوœھ被ن½؟能çڑ„وƒ…ه†µن¸‹ï¼Œهڈ‘ç”ںن؛†debugن؛‹ن»¶ï¼Œن¹ںهچ³و‰§è،Œو–点وŒ‡ن»¤
FORCED - ن¸ٹو–‡وڈگهˆ°çڑ„هڈ¯é…چç½®و•…éڑœهچ‡ç؛§ن¸؛ن؛†HardFault,وœ‰هڈ¯èƒ½وک¯ه› ن¸؛هڈ¯é…چç½®و•…éڑœhandlerو²،وœ‰è¢«ن½؟能,وˆ–者هœ¨handlerن¸ه¤„çگ†و—¶هڈˆهڈ‘ç”ںن؛†و•…éڑœ
VECTTBL - ç”±ن؛ژن»ژهگ‘é‡ڈè،¨ن¸è¯»ه‡؛هœ°ه€و—¶هڈ‘ç”ںو•…éڑœم€‚ن¸€èˆ¬ن¸چن¼ڑهڈ‘ç”ں,ن½†ه¦‚وœهگ‘é‡ڈè،¨ن¸وœ‰'هڈ'هœ°ه€ه¹¶ن¸”é预وœںن¸و–هڈ‘ç”ںو—¶ï¼Œè؟کوک¯هڈ¯èƒ½ن؛§ç”ںè؟™ن¸ھو•…éڑœ
وپ¢ه¤چçژ°هœ؛
ن¸؛ن؛†ن؟®ه¤چو•…éڑœï¼Œوˆ‘ن»¬éœ€è¦پçں¥éپ“و•…éڑœهڈ‘ç”ںو—¶و£هœ¨و‰§è،Œن»€ن¹ˆن»£ç پ,ه› و¤وˆ‘ن»¬éœ€è¦پهœ¨è؟›ه…¥ه¼‚ه¸¸و—¶èژ·هڈ–ه¯„هکه™¨çڑ„çٹ¶و€پم€‚
ه¦‚وœن½ وœ‰è°ƒè¯•ه™¨ï¼Œé‚£ه¾ˆه¥½ï¼Œوٹٹو–点و‰“هœ¨ه¼‚ه¸¸handler,

è؟›ه…¥ه¼‚ه¸¸ه‰چ,ç،¬ن»¶و€»وک¯ن¼ڑه°†ن¸€ن؛›ه¯„هکه™¨çڑ„ه†…ه®¹pushهœ¨و ˆé،¶م€‚Cortex-Mوœ‰ن¸¤ن¸ھSPوŒ‡é’ˆï¼Œmspه’Œpsp(ن¸چوک¯و¸¸وˆڈوژŒوœ؛ï¼پ),هœ¨ه¼‚ه¸¸ه…¥هڈ£ï¼ŒEXC_RETURNçڑ„bit 2çڑ„ه€¼ن»£è،¨ن؛†و؟€و´»çڑ„وک¯ه“ھن¸€ن¸ھSPوŒ‡é’ˆï¼Œه¦‚وœن¸؛1,那ن¹ˆوک¯psp被و؟€و´»ï¼Œهڈچن¹‹هˆ™وک¯mspم€‚
ن»¥ن¸‹و–¹ن»£ç پن¸؛ن¾‹ï¼Œ
int illegal_instruction_execution(void) {
int (*bad_instruction)(void) =(void *)0xE0000000;
returnbad_instruction();
}
ه½“هڈ‘ç”ںو•…éڑœو—¶ï¼Œهœ¨handlerن¸وˆ‘ن»¬هڈ¯ن»¥وں¥çœ‹و ˆçڑ„ه‰چه…«ن¸ھه€¼ï¼Œه®ƒن»¬وک¯r0, r1, r2, r3, r12, LR, pc, xPSR,وˆ‘ن»¬هڈ¯ن»¥ه¾—هˆ°ï¼ڑ
0x0 <g_pfnVectors>,
0x200003c4 <ucHeap+604>,
0x10000000,
0xe0000000,
0x200001b8 <ucHeap+80>,
0x61 <illegal_instruction_execution+16>,
0xe0000000,
0x80000000
让وˆ‘ن»¬وٹٹç›®ه…‰و”¾هœ¨LRه’Œpc,وˆ‘ن»¬ه°±èƒ½çں¥éپ“وک¯هœ¨ç¨‹ه؛ڈçڑ„ن»€ن¹ˆهœ°و–¹ï¼ˆillegal_instruction_executionن¸ï¼‰ن»¥هڈٹه…·ن½“و‰§è،Œن؛†ن»€ن¹ˆه‘½ن»¤ï¼ˆو‰§è،Œ0xE0000000هœ°ه€çڑ„وŒ‡ن»¤ï¼‰م€‚
ه½“然,ه®é™…هœ¨é،¹ç›®ه½“ن¸وˆ‘ن»¬è°ƒè¯•è؟‡ç¨‹ه€’ن¸چه؟…è؟™ن¹ˆé؛»çƒ¦ï¼Œن»¥EB Autosarن؛§ه“پن¸؛ن¾‹ï¼ˆو¬ çڑ„ه¹؟ه‘ٹè´¹ن»€ن¹ˆو—¶ه€™هˆ°è´¦TAT),ن½ 能ه¤ںن»¥ن¸€ç§چو›´هٹ 直观çڑ„و–¹ه¼ڈèژ·هڈ–هگ„ç§چن½ 需è¦پçڑ„ه€¼م€‚
و•…éڑœن¸çڑ„و•…éڑœï¼پ
وˆ‘çں¥éپ“وœ‰ن؛؛و¤و—¶éه¸¸ه…³ه؟ƒن¸€ن¸ھé—®é¢ک,è¦پوک¯هœ¨handlerن¸ه¤„çگ†و•…éڑœو—¶ï¼Œهڈ‘ç”ںن؛†ن¸€ن¸ھو–°çڑ„و•…éڑœï¼Œو€ژï¼پن¹ˆï¼پهٹï¼پ
ه…¶ه®ن¸ٹو–‡ن¹ںوœ‰وڈگهˆ°ï¼Œه¦‚وœهœ¨ن½؟能ن؛†هڈ¯é…چç½®و•…éڑœhandlerçڑ„وƒ…ه†µن¸‹ï¼Œهœ¨ه…¶ن¸ن؛§ç”ںن؛†و–°çڑ„و•…éڑœو—¶ï¼Œن¼ڑ触هڈ‘HardFaultم€‚
ن¸€و—¦هœ¨HardFaultن¹‹ن¸ï¼ŒARM Coreè؟گè،Œهœ¨ن¸€ن¸ھن¸چهڈ¯é…چç½®ن¼که…ˆç‰ç؛§â€”— -1,و¤و—¶ن¸€ن¸ھو–°çڑ„و•…éڑœن¼ڑ让ه¤„çگ†ه™¨è؟›ه…¥ن¸€ن¸ھن¸چهڈ¯وپ¢ه¤چçڑ„çٹ¶و€پ,ن¸”需è¦پreset,è؟™ç§چçٹ¶و€پهڈ«هپڑLockupم€‚
ن¸چè؟‡ï¼Œه¦‚وœن½ وک¯è؟وژ¥ç€è°ƒè¯•ه™¨ï¼ŒLockupهœ¨و¤و—¶ه°±ن¸چن¼ڑه¯¼è‡´resetم€‚
è‡ھهٹ¨وپ¢ه¤چ
هڈ¯èƒ½ن½ ن¹ںو„ںهڈ—هˆ°ن؛†ï¼Œه¾ˆه¤ڑو—¶ه€™وˆ‘ن»¬ه¹¶ن¸چ能精ç،®هœ°وŒ‡ه‡؛وک¯ن½•ه¤„çڑ„ن»£ç پهڈ‘ç”ںé—®é¢ک,ه¯¹ن؛ژMCUو¥è¯´هڈ¯èƒ½ن½؟用resetوک¯ن¸€ç§چوœ€ç®€هچ•وœ€و— è„‘çڑ„وپ¢ه¤چو–¹ه¼ڈم€‚ن¸چè؟‡ه¯¹ن؛ژه¦‚ن»ٹçڑ„Autosar程ه؛ڈو¥è¯´ï¼Œه®¢وˆ·çˆ¸çˆ¸ن¼ڑوœ‰و›´ç»†هŒ–çڑ„需و±‚,و¯”ه¦‚ن»…ن»…é‡چç½®وںگن¸€ن¸ھه؛”用程ه؛ڈوˆ–者وںگن¸€ن¸ھه؛”用هˆ†هŒ؛م€‚
Anyway,ن½œن¸؛Autosarه؛•ه±‚软ن»¶ï¼Œه·²ç»ڈوڈگن¾›ن؛†ه°½هڈ¯èƒ½ه¤ڑçڑ„错误ن؟،وپ¯ï¼Œه¦‚ن½•ه®ڑهˆ¶ç–略,ن»¥هڈٹه¦‚ن½•هچ•ç‹¬é‡چç½®Autosarه؛”用,وœ¬و–‡ن¸چن¼ڑو¶‰هڈٹم€‚
ه‡ ç§چه…¸ه‹çڑ„错误
eXecute Never Fault
int illegal_instruction_execution(void) {
int (*bad_instruction)(void) =(void *)0xE0000000;
returnbad_instruction();
}
è؟™و®µن»£ç پن¸ٹé¢ه·²ç»ڈوڈگهڈٹ,ه¦‚وœه°è¯•و‰§è،Œ0xE0000000هœ°ه€ï¼Œن¼ڑè؟›ه…¥HardFaultم€‚
读هڈ–'هڈ'هœ°ه€
uint32_t read_from_bad_address(void) {
return*(volatile uint32_t *)0xbadcafe;
}
ه¦‚وœه°è¯•ن»ژن¸€ن¸ھ读ن¸چهˆ°çڑ„هœ°ه€èژ·هڈ–و•°وچ®و—¶ï¼Œن¼ڑ触هڈ‘Bus Faultم€‚
هچڈه¤„çگ†ه™¨و•…éڑœ
void access_disabled_coprocessor(void) {
// FreeRTOS will automatically enable the FPU co-processor.
// Let's disable it for the purposes of this example
__asmvolatile(
"ldr r0, =0xE000ED88 \n"
"mov r1, #0 \n"
"str r1, [r0] \n"
"dsb \n"
"vmov r0, s0 \n"
);
}
هœ¨وˆ‘ن»¬و²،وœ‰ن½؟能هچڈه¤„çگ†ه™¨çڑ„وƒ…ه†µن¸‹ï¼Œن½؟用类ن¼¼ن؛ژvmov(وµ®ç‚¹وŒ‡é’ˆوŒ‡ن»¤ï¼‰è؟™و ·çڑ„وŒ‡ن»¤و—¶ï¼Œن¼ڑه¯¼è‡´coprocessor faultم€‚
Imprecise Fault
void bad_addr_double_word_write(void) {
volatileuint64_t *buf = (volatile uint64_t *)0x30000000;
*buf= 0x1122334455667788;
}
و‰§è،Œè؟™و®µن»£ç پ,è؟›ه…¥ه¼‚ه¸¸ه¹¶وں¥çœ‹IMPRECISERRه€¼و—¶ï¼Œن½ ن¼ڑهڈ‘çژ°و¤و—¶ه€¼ن¸؛1,那ن¹ˆوˆ‘ن»¬و‰€èژ·هڈ–هˆ°çڑ„و•…éڑœهœ°ه€ه¹¶ن¸چ能ç،®هˆ‡ن»£è،¨ه®é™…ه¯¼è‡´و•…éڑœçڑ„ن»£ç پم€‚
é‚£هڈھه¥½هœ¨و‰€وŒ‡هœ°ه€é™„è؟‘看看وœ‰ن»€ن¹ˆن»£ç پهڈ¯èƒ½ن¼ڑه¯¼è‡´è؟™ن¸ھé—®é¢کم€‚
ه¦‚وœوک¯M3وˆ–M4ç³»هˆ—,ن½ هڈ¯ن»¥é€ڑè؟‡ن½؟能Auxiliary Control Register (ACTLR)çڑ„DISDEFWBUF bitن½چو¥ç¦پو¢و‰€وœ‰çڑ„ه†™ه…¥ç¼“هکو“چن½œï¼Œè؟™و ·ن½ ه°±هڈ¯ن»¥éپ؟ه…چIMPRECISERRن¸؛1çڑ„وƒ…ه†µم€‚—— ه½“然,è؟™ن¸ھه¯¹و€§èƒ½وک¯وœ‰ه½±ه“چçڑ„م€‚
و‰€ن»¥ï¼Œه¯¹ن؛ژM7و¶و„çڑ„S32Gو¥è¯´ï¼Œو— و³•هپڑهˆ°ه¼؛هˆ¶و‰€وœ‰هکه‚¨و“چن½œéƒ½وک¯هگŒو¥çڑ„,那ن¹ˆن¹ںه°±و— و³•ç²¾ç،®èژ·هڈ–و•…éڑœهœ°ه€ن؛†م€‚
(و‰€ن»¥ن¸چè¦په†چé—®وˆ‘S32G能ن¸چ能精ç،®ه¾—هˆ°و•…éڑœهœ°ه€ن؛†م€‚臣ه¦¾هپڑن¸چهˆ°ه“‡ --->ن¸چè؟‡ه¦‚وœهڈ‘çژ°و¶و„وœ‰هچ‡ç؛§وˆ–者Armو–‡و،£وœ‰و›´و–°ï¼Œو¬¢è؟ژ讨è®؛)
هڈ‚考
How to debug a HardFault on an ARM Cortex-M MCU | Interrupt (memfault.com)
ARM Cortex-M7 Processor Technical Reference Manual r0p2
Arm Cortex-M7 Devices Generic User Guide r1p2
ه›¾ç‰‡و¥è‡ھ网络,ه¦‚وœ‰ن¾µوƒï¼Œè¯·èپ”ç³»هˆ 除