Micropython 是 Python 3.6 的另一种实现,支持全部常用的 Python 语法。MicroPython 也是 Python 的一个精简版本,它是为了运行在单片机这样的性能有限的微控制器上,最小体积仅 256 K,运行时仅需 16 K 内存,但这样寒酸的配置基本上也只能运行最简单的脚本了。若要使用功能比较完整的配置,建议配置 512 KB Flash 和 64 KB RAM,或者更大。
Micropython 为了适应嵌入式微控制器,裁剪了大部分标准库,仅保留部分模块如 math、sys 的部分函数和类。此外,很多标准模块如 json、re 等在 MicroPython 中变成了以 u 开头的 ujson、ure,表示针对 MicroPython 开发的标准库。
Micropython 中的“micro”容易让人以为它只是在 Python 上减少功能。其实不然,它也为了适合在 MCU 上使用而增加了新的功能和特点。比如,在 Micropython 上,对于性能和实时性有要求的部分可以仍然使用 C 来编程,并且导出绑定到 Python 的接口,一般可以做到易用和严肃开发的兼顾。Micropython 本身也通过一些特殊的扩展和模块来支持在 MCU 更高效和底层的操作,包括 native修饰,以不使用动态内存换性能的 viper 修饰,可以直接访问地址空间的 mem8/16/32 模块,甚至直接内联汇编等。
工作原理
归纳为:编译,执行。
编译
MicroPython 中的编译过程包括以下步骤:
- 词法分析器将组成 MicroPython 程序的文本流转换为标记。- 然后解析器将标记转换为抽象语法(解析树)。
- 然后基于解析树发出字节码或本机代码。
参见:
http://micropython.com.cn/en/latet/develop/compiler.html
https://github.com/micropython/micropython/tree/master/mpy-cross
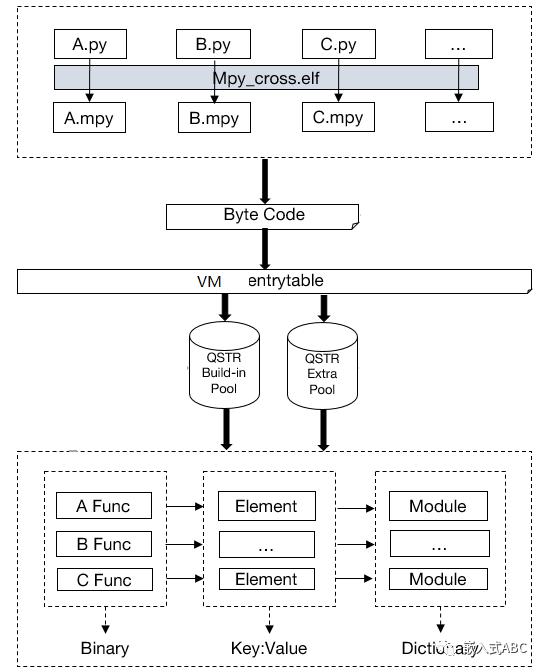
交叉编译器mpy-cross将.py文件编译成.mpy文件。.mpy 文件是一种包含预编译代码的二进制容器文件格式。对于某些体系结构,.mpy 文件还可以包含本地机器代码,这些代码可以通过多种方式生成,最显着的是从 C 源代码生成。
执行
QSTR是uniQue STRing的简称,是一种字符串内存驻留方法。我们知道同一个标识符可能在源代码中出现多次,如果我们在每个出现的地方都要保留一份这个标识符的拷贝,就会相当占用存储空间。Micropython采取的方式是在存储空间内仅保留一份标识符主体,而每个标识符主体都有一个索引号,代码中凡是使用这个标识符的地方,都使用其索引号代替。而最终执行时就通过这个索引号去内存中寻找对应的标识符。这就是Micropython中所谓的QSTR。Micropython的C代码中所有需要使用QSTR的地方都用MP_QSTR_xxx表示,比如lcd就用MP_QSTR_lcd表示,这个MP_QSTR_lcd就是lcd这个标识符的索引号。Micropython的Makefile会搜索C源文件中的所有MP_QSTR_xxx,并生成QSTR池,其中存放了QSTR对应的标识符的长度和哈希值。Micropython的C代码中的QSTR定义最终会被放入mpy-cross/build/genhdr/qstrdefs.generated.h中。
Byte Code在执行时会依赖Virtual Machine入口表,找到对应的Module入口,最终找到对应的Funcion binary code执行。其中所有的Function都通过Dictionary的形式存储,而每一个Dictionary都有自己的QSTR,Micropython有buildin的QSTR和用户扩展的QSTR。
开发、部署、执行 Python 脚本的方式
归纳为如下三种方式:
在交互式开发环境中使用MicroPython: REPL 代表 Read Evaluate Print Loop,是可以在 pyboard 上访问的交互式 MicroPython 提示的名称。到目前为止,使用 REPL 是测试代码和运行命令的最简单方法. 打开串行程(PuTTY、screen、picocom 等)后,看到一个带有闪烁光标的空白屏幕。按 Enter 键,看到 MicroPython 提示即>>>.
通过PC访问microPython文件系统:通过 PC 访问 Micropython 文件系统是极为重要的,这是因为在 Micropython 上缺少好用 Python 编辑器。我们常常是在 PC 上使用自己喜欢的编辑器书写 Python 代码。写好的代码需要下载到 Micropython 的文件系统上。
交叉编译,固化执行:这和 C 语言项目开发习惯比较接近。需要我们在宿主机上使用 Micropython 提供的交叉编译工具,一个名叫 mpy-cross 的程序,来把 Python 代码编译成 Micropython 的虚拟机可以解的字节码。字节码被封装成一个特殊的可执行对象,并序列化为 C 源代码,放置到 Micropython 的工程中,随其它源码一起编译和链接
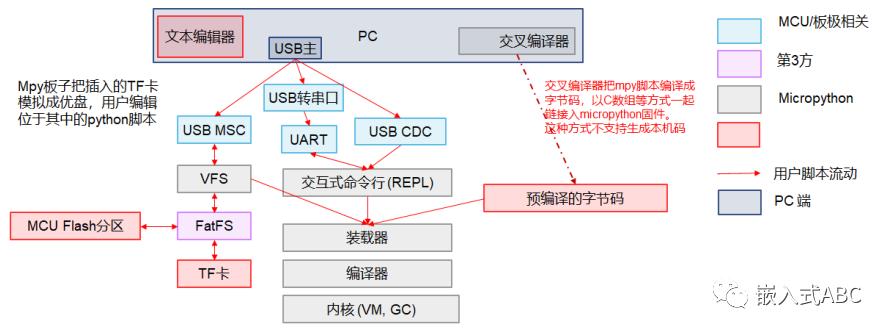
使用“交叉编译,固化执行”方式可以从固件中剪裁掉 Micropython 编译器,节省少量 Flash 空间。但是由于这种方式牺牲了快速运行不同代码的便利。有些基于 Micropython 的项目,如 Micro:bit,就使用这种方式。
Micropython 中的库
学习一门语言,有相当大的比重是熟悉它的库。语言越高级,对于库的学习就越重要。C 语言的库比较单薄,C++库就丰富得多了。而对于 Python,语言本身非常容易入门,对各种库的了解和运用反而更加重要,Micropython 也同样如此。在这里简要介绍一下。
模块与类型
Micropython 下,库一般有两种呈现形式:
模块:
通过“import <module_name>”使用。在导入了模块后,就可以使用它里面的方法和类型了。这里的方法其实就像是函数调用,它们没有与之关联的对象实例,有些语言也称之为静态方法。类型:类型由模块提供,它们好比是面向对象语言中的类,封装了数据和操作。在 C 语言中,其实就是在某个结构体,以及所有能操作这个结构体的实例的函数。在使用它们时,先创建出某个类型的对象,然后就可以调用对象上的方法了。
精简的 Python 标准库
作为 Python 3 的一个精简实现,Micropython 也携带了常用的 Python 库,大多亦被精简成微型库。微型库以“u”开头,只实现了CPython 模块功能的一个子集
与 MCU 和电路板的硬件相关的库
在 Micropython 中,通过 Python 模块和 Python 模块创建出来的对象来封装 MCU 和电路板上的资源。封装的方式有两种:
面向外设式:这也是最直接的封装方式,就仿佛是通过 Python 使用的基础 SDK,以驱动常用的外设。如果要使用以这种方式封装的 Python 模块和对象,需要对相应的外设类别有基础的了解。例如,ADC,I2C,UART,SPI 等,它们名字一般与外设同名。这类功能大多封装在 pyb 模块和 machine 模块中。
面向应用场景式:相比面向外设式的 API,它们更加针对某一个具体的使用方式。例如,LED 类型,它直接提供基础 LED控制的 API,但是底层在实现是自动调用 GPIO 和 PWM(带调光功能时)。它们提供的方法常常更方便特定应用场景的使用。
有一些简单的功能,例如 Pin 类型,它封装了 GPIO 的功能,兼有两者的特点。参见 http://micropython.com.cn/en/latet/library/pyb.Pin.html#pyb-pin
用好带垃圾回收(GC)功能的动态内存管理器
对 Micropython 的使用有了初步了解后,还是需要再多了解一点垃圾回收这块,这毕竟与使用 C 语言编程的内存管理哲学完全相反——相信程序员 VS. 不相信程序员!
在 C 语言中,我们必须自己管理内存,清楚地知晓静态内存、栈内存和堆内存的区别,以及各变量,尤其是指针变量,是如何安置的,作用域如何。特别地,对于通过 malloc 得到的动态内存,必须小心翼翼地管理它们的生存期,以及指针的数目,稍不留神就可能埋下隐蔽的安全隐患。这也是 C 语言“一切相信程序员”的哲学带来的结果:我们在享受至高无上的内存使用权力时,也要承受事无巨细的内存管理的义务。最常见的麻烦事之一,就是为每个 malloc 配对一个 free。
在 Python 中,这种权力和义务被收回了。我们在使用任何 Python 对象的时候,都无需手动分配和释放它们的内存,Python 语言的运行环境接管了这一切,在 Micropython 中也是这样。如果你使用 Python 只是为了让计算机系统以可编程的方式给你干活,那这种方式无疑是莫大的解放:要成为 Python 程序员不再首先得成为一个系统软件程序员了,我们可以集中精力对付自己的应用要解决的问题,而不用亲自处理内存管理的繁文缛节。
事实上,Python 中的对象也是从一个堆内存分配出来的,这个堆的管理器也同样有 malloc 和 free 的方法。但不同的是,这个堆管理器还记录了其它的一些线索,可以知道某一时刻哪些它正在管理的内存块还在使用中,并且自动为不再使用的内存块调用 free 操作。这个功能在 Micropython 中叫作 Garbage Collector (GC),它基本上是一个基于定长块的分配器,只是它一次可以分配多个连续的块。块的长度是 2 的方幂,一般在 16 字节以上。
Gc 使用双位数组来跟踪各个块的分配情况。当 gc 发现没有可用内存可供分配时,就启动垃圾回收操作。gc 会扫描脚本的栈和当前寄存器,以及一个特殊的“root pointer”清单,查找它们之中是否有可以当作指针来解读的 32 位变量,并且指向了自己分配出去的内存。只要找到了,就会标记这段内存的所有块为“它们不是垃圾”。这还不算完,它还会扫描所有“不是垃圾”的内存块的内容,以对齐的 4 字节为单位,全部当作潜在的指针来处理。只要发现任何一个潜在的指针指向了自己分配的某段内存,就把这段内存也当作“不是垃圾”。这个操作被递归地执行。这非常像筛查新冠肺炎的感染者和他们的密切接触者,以及密切接触者的密切接触者……。最后,那些与“不是垃圾”的内存没有关系的内存块,就会被当作是垃圾,并且被 free 掉。分析上面的过程,可知这个递归的过程是非常不确定的。如果给 gc 管理的内存容量大,块的粒度小,Python 程序中使用的变量多,变量之间的引用又盘根错节的话,这种递归式的筛查可以消耗大量的时间,甚至长达十万个 CPU 周期以上!在此期间,脚本是不能执行的。所以,对于绝大多数硬实时的控制系统,都不可能接受这种最坏情况的响应延迟。在实践中,为了使基于 Micropython的系统能满足更多的实时应用,常常把实时任务由底层的 C 语言部分实现,并且手动管理它们的内存。
即使是在 Python 语言层面,也有方法尽量降低捡垃圾所带来的不确定性。Gc 把一些关键的功能绑定到了一个名为“gc”的 Python模块上。它有一个重要的方法叫“collect()”。在写 Python 脚本时,如果意识到自己的脚本会快速生产和消费大量的内存块——也就是快速制造内存垃圾,可以适当插入一些“gc.collect()”调用,以更加频繁地“大扫除”,避免垃圾“堆积如山”后才花大量时间做一次大扫除。当然,这个代价是降低垃圾的回收效率,也就是以牺牲整体性能为代价降低不确定性。
参见 http://micropython.com.cn/en/latet/develop/memorymgt.html
用 C 扩展 MicroPython
当由于Python 环境的限制,无法访问某些硬件资源或 Python 速度限制时,可行的选择:
用C(和/或 C++)编写部分或全部模块,再将此类外部模块编译为 MicroPython 可执行文件或固件映像
另一种方法是 在 .mpy 文件中 使用本机机器代码,它允许编写放置在 .mpy 文件中的自定义 C 代码,该代码可以动态导入到正在运行的 MicroPython 系统中,而无需重新编译主固件
MicroPython 外部 C 模块, 参见 http://www.86x.org/en/latet/develop/cmodules.html
.mpy 文件中的本机机器代码,参见
http://www.86x.org/en/latet/develop/natmod.html?highlight=mpy tool py#
参考
http://micropython.com.cn/en/latet/pyboard/tutorial/leds.html
https://www.nxp.com.cn/docs/zh/application-note/AN13242.pdf
https://developer.aliyun.com/article/740410
https://makeblock-micropython-api.readthedocs.io/zh/latest/novapi/tutorial/precompiled_to_mpy.html