大家好呀,今天继续给大家分享一些优质面试题,希望对正在找工作的小伙伴有所帮助。
后端
题目一
什么是 RPC?目前有哪些常见的 RPC 框架?实现 RPC 框架的核心原理是什么?
官方解析
RPC(Remote Procedure Call)是一种远程调用协议,允许一台计算机通过网络调用另一台计算机上的服务或方法。它可以让开发人员像调用本地方法一样调用远程方法,将网络通信细节封装起来,提高了分布式系统中各个模块之间的耦合性。
目前常见的 RPC 框架有:
RPC 框架的核心原理是基于网络传输协议实现的远程方法调用。RPC 框架通常由服务提供者和服务消费者两部分组成,服务提供者将本地方法暴露成远程服务,服务消费者通过远程代理对象调用远程方法。
在实现远程方法调用时,需要进行序列化和反序列化操作。序列化将对象转换为二进制数据流,以便于在网络中传输;反序列化则将接收到的二进制数据流转换为对象。
为了提高性能,一些 RPC 框架使用了二进制协议,如 Dubbo 使用的 Hessian2 协议和 gRPC 使用的 Protocol Buffers 协议,与基于文本的协议(如 XML 和 JSON)相比,二进制协议具有更小的传输体积和更高的解析速度,能够减少网络传输的开销。
鱼友的精彩回答
林寻的回答
RPC【Remote Procedure Call】是指远程过程调用,是一种进程间通信方式,他是一种技术的思想,而不是规范。它允许程序调用另一个地址空间(通常是共享网络的另一台机器上)的过程或函数,而不用程序员显式编码这个远程调用的细节。即程序员无论是调用本地的还是远程的函数,本质上编写的调用代码基本相同。
9915-java-木木的回答
什么是 RPC?RPC 是远程过程调用(Remote Procedure Call)的缩写,是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。
RPC 的主要功能目标是让构建分布式计算/应用更加容易,在提供强大的远程调用能力时不损失本地调用的语义简洁性。
常见的RPC框架- gRPC:是由 Google 开发的一个基于 HTTP/2和Protocol Buffers 的高性能、跨语言的 RPC 框架,支持多种编程语言,如:java、C++、Python 等。
- Dubbo:是由阿里巴巴开发的一个基于 java 的高性能、轻量级的 RPC 框架,支持多种协议和注册中心,如:zookeeper、Nacos 等等
- Thrift:是由 FaceBook 开发的一个基于二进制协议和多种传输层的 RPC 框架,支持多种编程语言,如:java、c++、Python 等
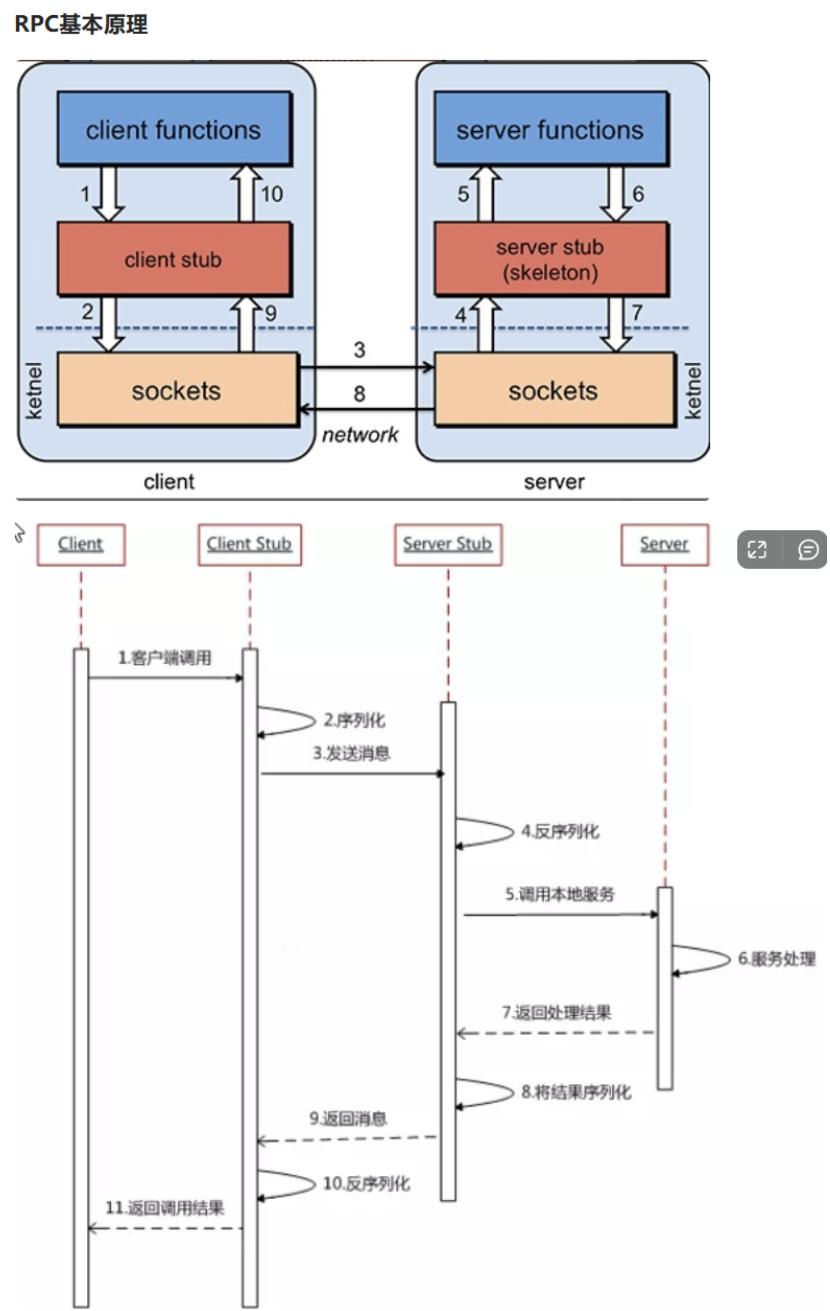
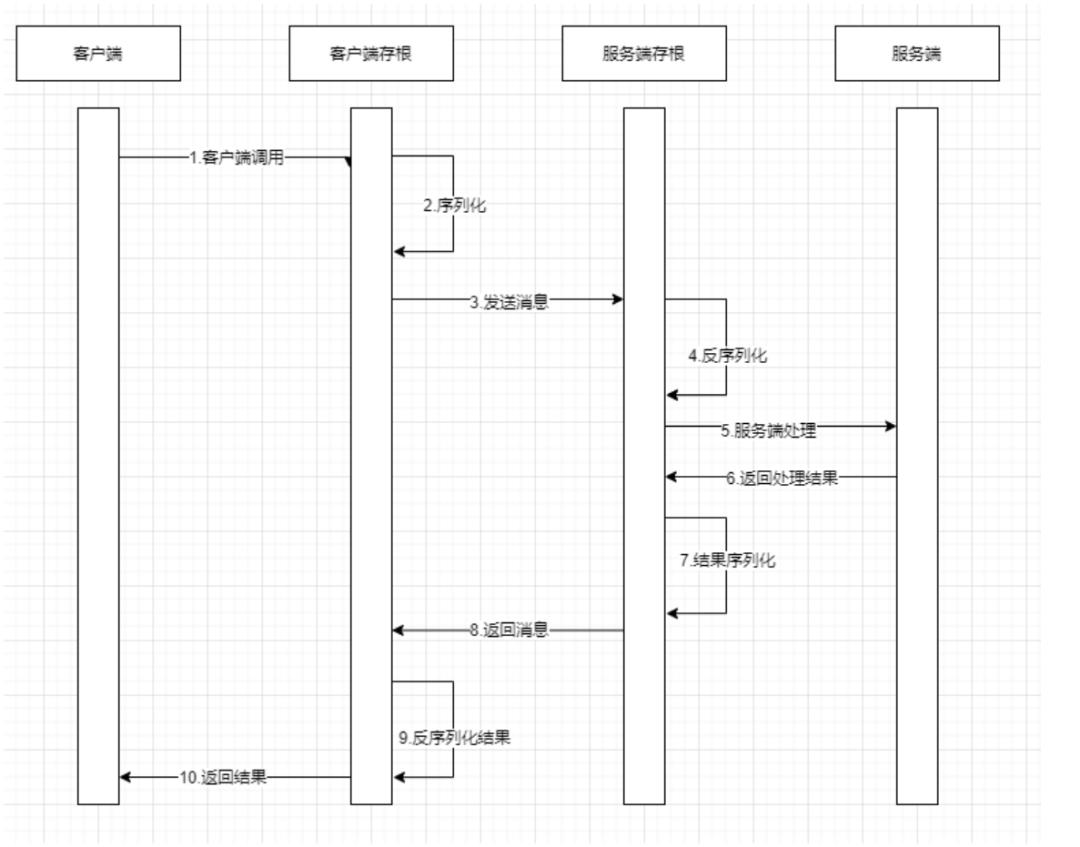
RPC 框架的核心原理是通过代理、序列化、网络传输、反序列化、反射等技术,实现远程过程调用的透明化。核心流程如下:
题目二
设计模式可以分为哪几类?一共有多少种主流的设计模式?
官方解析
设计模式可以分为三类:
创建型模式:这类模式关注对象创建的机制,包括单例模式、工厂模式、抽象工厂模式、建造者模式和原型模式等。
结构型模式:这类模式关注对象之间的组合关系,包括适配器模式、装饰器模式、代理模式、组合模式、桥接模式、外观模式和享元模式等。
行为型模式:这类模式关注对象之间的通信方式和协作方式,包括模板方法模式、策略模式、命令模式、职责链模式、状态模式、观察者模式、中介者模式和访问者模式等。目前主流的设计模式有23种,它们分别是:
单例模式
工厂方法模式
抽象工厂模式
建造者模式
原型模式
适配器模式
装饰器模式
代理模式
外观模式
桥接模式
组合模式
享元模式
策略模式
模板方法模式
观察者模式
迭代器模式
职责链模式
命令模式
备忘录模式
状态模式
访问者模式
中介者模式
解释器模式
鱼友的精彩回答
猫十二懿的回答
共五种设计模式:简单工厂模式、工厂方法模式、抽象工厂模式、单例模式和建造者模式。
共七种设计模式,分别是适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式和享元模式。
共十一种设计模式:策略模式、模板方法模式、观察者模式、迭代器模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式和解释器模式。主流的设计模式共有 23 种,它们是:
简单工厂模式(Simple Factory Pattern):一个工厂对象负责根据传入的参数创建不同的对象实例。
工厂方法模式(Factory Method Pattern):每个具体的类都有自己的工厂方法,负责创建对象实例。
抽象工厂模式(Abstract Factory Pattern):一组相关或相互依赖的对象,由一个抽象工厂对象负责创建。
单例模式(Singleton Pattern):确保类只有一个实例,并提供全局访问点。
建造者模式(Builder Pattern):将一个复杂对象的构建过程分解为多个简单对象的构建过程。
原型模式(Prototype Pattern):一种创建型设计模式,它通过克隆已有对象来创建新的对象,而不是通过实例化对象来创建。
适配器模式(Adapter Pattern):将一个类的接口转换成客户希望的另一个接口。
装饰器模式(Decorator Pattern):动态地为对象增加新的功能。
代理模式(Proxy Pattern):为其他对象提供一种代理以控制对这个对象的访问。
外观模式(Facade Pattern):为复杂的子系统提供一个简单的接口。
桥接模式(Bridge Pattern):将抽象部分与它的实现部分分离,使它们都可以独立地变化。
组合模式(Composite Pattern):将对象组合成树形结构以表示部分-整体的层次结构。
享元模式(Flyweight Pattern):通过共享技术来实现大量细粒度对象的复用。
策略模式(Strategy Pattern):定义一系列算法,将它们封装起来,并且使用他们可以相互替换。
模板方法模式(Template Method Pattern):定义一个算法的骨架,将一些步骤延迟到子类中实现。
观察者模式(Observer Pattern):定义对象间的一种一对多的依赖关系,当一个对象状态发生改变时,所有依赖于它的对象都得到通知并自动更新。
迭代器模式(Iterator Pattern):提供一种方法顺序访问一个聚合对象中各个元素,而且又不暴露该对象的内部表示。
责任链模式(Chain of Responsibility Pattern):为某个请求创建一个对象链,处理该请求的对象沿着该练依次处理,知道一个对象处理它为止。
命令模式(Command Pattern):将一个请求封装成一个对象,使发出请求的责任和执行请求的责任分割开。
备忘录模式(Memento Pattern):它允许在不暴露对象实现细节的情况下,保存和恢复对象之前的状态。
状态模式(State Pattern):允许对象在其内部状态改变时改变它的行为。
访问者模式(Visitor Pattern):封装一些作用于某种数据结构中的各元素的操作,它可以在不改变这个数据结构的前提下定义作用于这些元素的新操作。
中介者模式(Mediator Pattern):通过封装一系列对象之间的交互,来降低对象之间的耦合度。
题目三
如何在 10 亿个数据中找到最大的 1 万个?(提示:最小堆)
官方解析
在 10 亿个数据中找到最大的 1 万个,可以使用最小堆(Min-Heap)算法来实现。
最小堆是一种特殊的二叉树结构,每个节点的值都小于或等于其左右子节点的值。在使用最小堆来查找最大的 1 万个数据时,可以先创建一个大小为 1 万的最小堆,然后将 10 亿个数据逐个加入堆中。当堆的大小超过了 1 万时,将堆顶元素(即最小值)弹出,再将当前元素加入堆中。当遍历完所有数据后,堆中剩余的 1 万个元素就是最大的 1 万个数据。
这种方法的时间复杂度为 O(n log k),其中 n 是数据总数,k 是要查找的元素数量。因为要维护一个大小为 1 万的最小堆,所以空间复杂度也为 O(k)。
以下是一个示例代码:
import heapq
def find_largest_10000(data):
heap = []
for d in data:
if len(heap) < 10000:
heapq.heappush(heap, d)
else:
heapq.heappushpop(heap, d)
return heap
在这个示例代码中,我们使用了 Python 的内置模块 heapq 来实现最小堆。
函数 find_largest_10000 接受一个包含 10 亿个数据的列表,然后返回最大的 1 万个数据。这个函数使用了一个大小为 1 万的最小堆来维护当前找到的最大的 1 万个数据。对于每个数据,如果堆的大小小于 1 万,则直接将数据加入堆中;否则,先将数据加入堆中,再弹出堆顶元素,保证堆的大小不超过 1 万。最后,函数返回堆中剩余的 1 万个元素,这些元素就是最大的 1 万个数据。
鱼友的精彩回答
Gundam的回答
使用最小堆来解决:
首先,我们可以把这 10 亿个数据划分成多个小数据块,每个小数据块包含 1 万个数据。然后,我们可以遍历这些小数据块,对于每个小数据块,我们可以构建一个大小为 1 万的最小堆。当遍历到一个新的数据时,我们可以把它与最小堆的堆顶元素进行比较。如果这个数据比堆顶元素大,那么我们可以把堆顶元素删除,并把这个数据插入到最小堆中。这样,当我们遍历完所有的小数据块之后,最小堆中存储的就是最大的 1 万个数据了。
具体实现过程如下:
- 如果数据比堆顶元素大,那么删除堆顶元素,并把这个数据插入到堆中。
- 如果数据比堆顶元素小,那么忽略这个数据。
这种方法的时间复杂度是 O(NlogK),其中 N 是数据总数,K 是需要找到的最大的数据数量。因为最小堆的大小是固定的,所以时间复杂度与数据总数 N 没有关系,只与需要找到的数据数量 K 有关系。因此,这种方法可以快速找到最大的 1 万个数据,而且可以处理非常大的数据集。
维萨斯的回答
一句话大根堆找 TOP 小
小根堆找 TOP 大
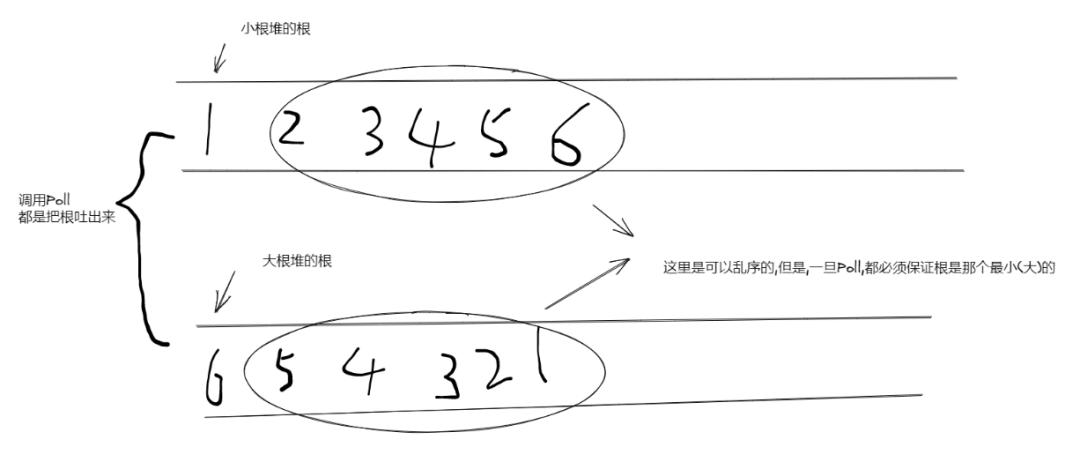
看着图再思考答案的合理性就简单了
- TOP 大 -> 小根堆
- 一边看图一边理解思路
- 先把前 1 w 个推进小根堆
- 然后
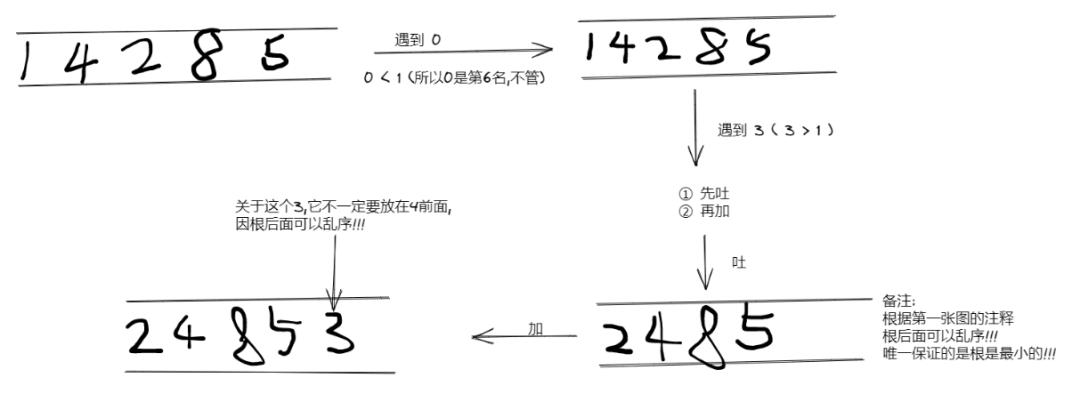
- 具体思考过程:
- 因为小根堆是: 根最小,那么说明,根后面的都比大,根就是那个第1W名
- 所以,处理后面的数字,当遇到比根还小的 ( 说明他怎么都是10001名 ) -> 不管
- 遇到比根大的 ( 说明他可以抢占第 1 W 名甚至第1名 ) -> 弹出根,然后把那个新的数字加进来
- 最后小根堆中的那 1 W 个就是 TOP10000 了
备注: 下面的模拟是我用 IDEA 使用 PriorityQueue 进行 Debug 的,具体根后面是否可以乱序,我不知道其它语言怎么样,但是 JAVA 的优先队列是可以乱序的
JIA 的回答
最容易想到的方法是将数据全部排序,然后在排序后的集合中进行查找,最快的排序算法的时间复杂度一般为 O(nlogn),如快速排序。但是在 32 位的机器上,每个 float 类型占 4 个字节,1 亿个浮点数就要占用 400 MB 的存储空间,对于一些可用内存小于 400 M 的计算机而言,很显然是不能一次将全部数据读入内存进行排序的。其实即使内存能够满足要求(我机器内存都是 8 GB),该方法也并不高效,因为题目的目的是寻找出最大的 10000 个数即可,而排序却是将所有的元素都排序了,做了很多的无用功。
第二种方法为局部淘汰法,该方法与排序方法类似,用一个容器保存前 10000 个数,然后将剩余的所有数字——与容器内的最小数字相比,如果所有后续的元素都比容器内的 10000 个数还小,那么容器内这个 10000 个数就是最大 10000 个数。如果某一后续元素比容器内最小数字大,则删掉容器内最小元素,并将该元素插入容器,最后遍历完这 1 亿个数,得到的结果容器中保存的数即为最终结果了。此时的时间复杂度为 O(n+m^2),其中 m 为容器的大小,即 10000。
第三种方法是分治法,将 1 亿个数据分成 100 份,每份 100 万个数据,找到每份数据中最大的 10000 个,最后在剩下的 100*10000 个数据里面找出最大的 10000 个。如果 100 万数据选择足够理想,那么可以过滤掉1亿数据里面 99% 的数据。100万个数据里面查找最大的 10000 个数据的方法如下:用快速排序的方法,将数据分为 2堆,如果大的那堆个数 N 大于 10000 个,继续对大堆快速排序一次分成 2 堆,如果大的那堆个数 N 大于 10000 个,继续对大堆快速排序一次分成 2 堆,如果大堆个数 N小于 10000 个,就在小的那堆里面快速排序一次,找第 10000-n 大的数字;递归以上过程,就可以找到第 1 w 大的数。参考上面的找出第 1 w 大数字,就可以类似的方法找到前 10000 大数字了。此种方法需要每次的内存空间为 10^6*4=4MB,一共需要 101 次这样的比较。
第四种方法是 Hash 法。如果这 1 亿个书里面有很多重复的数,先通过 Hash 法,把这 1 亿个数字去重复,这样如果重复率很高的话,会减少很大的内存用量,从而缩小运算空间,然后通过分治法或最小堆法查找最大的 10000 个数。
第五种方法采用最小堆。首先读入前 10000 个数来创建大小为 10000 的最小堆,建堆的时间复杂度为 O(mlogm)(m 为数组的大小即为 10000),然后遍历后续的数字,并于堆顶(最小)数字进行比较。如果比最小的数小,则继续读取后续数字;如果比堆顶数字大,则替换堆顶元素并重新调整堆为最小堆。整个过程直至 1 亿个数全部遍历完为止。然后按照中序遍历的方式输出当前堆中的所有 10000 个数字。该算法的时间复杂度为 O(nmlogm),空间复杂度是 10000(常数)。
爱吃鱼蛋 的回答
方法在10亿个数据中找到最大的 1 万个,可以使用以下算法:
其中 Top-K 算法通常使用的是最小堆实现。最小堆是一种基于树的数据结构,它的根节点是最小的元素,每个节点的值都小于或等于其子节点的值。在 Top-K 算法中,我们可以使用最小堆来维护当前找到的最大的 K 个元素。具体实现方式是
- 将数据集中的前 K 个元素构建成一个最小堆;
- 遍历剩余的数据:
- 如果当前数据比堆顶元素小,跳过;
- 如果当前数据比堆顶元素大,则将堆顶元素替换成当前元素,并重新调整最小堆。
- 重复这个过程,直到遍历完所有数据,最终得到的就是最大的 K 个元素。
在Java中,我们可以使用Java 内置的 PriorityQueue 优先队列来实现最小堆。具体实现如下:
- 创建一个大小为 k 的 PriorityQueue 对象 queue,用来存储当前找到的最大的 k 个数;
- 遍历 nums 数组,对于每个元素:
- 如果 queue 的大小小于 k,将其加入 queue 中;
- 如果 queue 的大小等于 k,比较当前元素与 queue 的堆顶元素的大小,如果当前元素大于堆顶元素,则将堆顶元素弹出,将当前元素加入 queue 中;
- 遍历完成后,queue 中存储的就是最大的 k 个元素;
- 将 queue 中的元素依次弹出,存入结果数组 result 中,返回结果数组。
public class TopK {
public static void main(String[] args) {
// 定义模拟数据
int[] nums = {3, 5, 1, 7, 8, 2, 9, 4, 6};
// 定义需要找的top k
int k = 3;
// 拿到top k数组
int[] result = topK(nums, k);
for (int i = 0; i < result.length; i++) {
System.out.print(result[i] + " ");
}
}
/**
* top-k算法(最小堆实现)
* @author: yudan
*/
public static int[] topK(int[] nums, int k) {
// 定义优先队列充当最小堆
PriorityQueue<Integer> queue = new PriorityQueue<>(k);
// 遍历数组
for (int num : nums) {
if (queue.size() < k) {
// 保证堆中永远都有且只有k个元素
queue.offer(num);
} else {
// 与堆顶元素比较进行更换
if (num > queue.peek()) {
queue.poll();
queue.offer(num);
}
}
}
// 出队将结果放入数组中返回
int[] result = new int[k];
for (int i = 0; i < k; i++) {
result[i] = queue.poll();
}
return result;
}
}
优化思路当然,上面的情况只是最简单的情况,对于10亿数据中找最大的1万个,虽然也能用上面的方式,但是很容易造成处理时间过长甚至OOM问题,因此针对这些问题可以采用以下方式进行优化:
- 对数据进行分块处理,每次只处理一部分数据,这样可以避免一次性将所有数据读入内存中;
- 使用线程池处理分块数据,采取并行的方式提高处理的速度,但需要考虑并发问题;
- 使用外部排序等方法将数据分块排序,然后再合并排序后的结果,这样可以避免一次性对所有数据进行排序;
- 调整JVM的堆内存大小,增大堆内存的大小可以提高处理大规模数据的能力,但是也会增加系统的负担和风险;
- 使用分布式计算框架如Hadoop、Spark等来处理大规模数据,这样可以将数据分布在多台计算机上进行处理,大大提高处理能力和效率。
前端
题目一
CSS 有哪些常用单位?这些单位各有什么区别?
官方解析
CSS 中常用的单位有以下几种:
在使用 CSS 单位时,需要根据实际情况选择合适的单位。一般情况下,像素是最常用的单位,因为它在大多数情况下可以提供良好的显示效果。对于需要在不同设备上适配的情况,可以使用 em、rem 和 vw、vh 等相对单位。
鱼友的精彩回答
你还费解吗的回答
按类型划分,CSS 的单位可分为绝对长度单位和相对长度单位,常见的有:
绝对长度单位:px:CSS 像素,是最常用的一个单位,用于指定一个固定大小的元素——不会随设备(电脑、手机、ipad)的切换、页面的缩放而改变。
扩展:物理像素
1 个 CSS 像素并不一定等于 1 个物理/设备像素 dp,物理像素就是真正构成设备显示屏的一个个像素点。早期,1 个 px 等于 1 个 dp,但高清 2 倍屏、3 倍屏的出现,导致手机屏幕的尺寸没有变化,屏幕的分辨率却提高了一倍或几倍,即同样大小的屏幕上,像素多了一倍。比如,当设置某个元素的属性为 1px 时,我们期望的是该属性在屏幕上占据 1 个物理像素,这在普通屏幕上当然是满足的,但在 2 倍屏上,1 个 CSS 像素对应的却是 4 个物理像素点,这也就导致了移动端中的 1px 边框会偏粗。注意,px 单位的值必须是整数。
扩展:怎么解决移动端的 1 px 问题?
相对长度单位:- em:em 在设置自身字体大小 font-size 的时候是相对于父元素的字体大小,而设置其他属性(如width、height)的时候,是相对于自身的字体大小,如果没有设置,则继承父级元素,如果父级元素也没有,则相对于浏览器的默认字体大小。
注意:任意浏览器的默认字体大小都是16px,也就是说,所有未经调整的浏览器都符合: 1em = 16px。比如,12px = 0.75em,10px = 0.625em。
- rem:相对于 HTML 根元素 设置的字体大小,与 em 一样,如果没有设置则相对于浏览器的默认字体大小。这个单位可谓集相对单位和绝对单位的优点于一身,通过它既可以做到只修改根元素就成比例地调整所有字体大小,又可以避免字体大小逐层复合的连锁反应。在实际应用中,rem 经常被用于响应式布局,以便元素可以根据视口大小进行自适应调整。目前,除了 IE8 及更早版本外,所有浏览器均已支持 rem。
扩展:如何通过 rem 实现简单的响应式布局?/ rem 适配方案?
%:百分比,当父元素的某些属性发生变化时,通过百分比可让元素也随之发生改变,从而实现响应式的效果。在某些属性中百分比相对于自身,比如 translate、border-radius 等。
vw 和 vh:vw/vh 是与视图窗口有关的单位,vw 表示相对于视图窗口的宽度,长度等于视口宽度的 1/100;vh 表示相对于视图窗口高度,长度等于视口高度的 1/100。
vmin 和 vmax:vmin 取 vw 和 vh 中的较小值;vmax 取 vw 和 vh 中的较大值;
扩展:用过vw 和 vh 吗?应用场景是什么?
还有一些单位,不过极少使用,了解即可:
- cm:厘米(1cm = 96px/2.54)
- mm:毫米(1mm = 1/10th of 1cm)
- in:英寸(1in = 2.54cm = 96px)
- Q:四分之一毫米(1Q = 1/40th of 1cm)
- pt:点(1pt = 1/72 of 1in)
- pc:派卡 (1pc = 1/6th of 1in)
- ch:相对于数字 “0” 的宽度
- ex:相对于字符 “x” 的高度
- lh:元素的 line-height
题目二
React.memo() 和 useMemo() 的用法是什么,有哪些区别?
官方解析
React.memo() 和 useMemo() 是 React 中用于性能优化的两个钩子函数。
React.memo() 是一个高阶组件,用于优化组件的性能。它会比较组件的新旧 props,如果 props 没有发生改变,则跳过渲染,直接使用上一次渲染的结果。使用 React.memo() 可以避免组件不必要的重新渲染,从而提高应用程序的性能。
用法示例:
const MemoizedComponent = React.memo(MyComponent);
useMemo() 是一个 Hook,用于缓存函数的计算结果。它可以缓存组件的 props 或其他数据的计算结果,只有当依赖项发生改变时才重新计算。
用法示例:
const memoizedValue = useMemo(() => computeExpensiveValue(a, b), [a, b]);
区别:
- React.memo() 用于优化组件的性能,它会比较组件的新旧 props,如果 props 没有发生改变,则跳过渲染,直接使用上一次渲染的结果。而 useMemo() 用于缓存函数的计算结果,只有当依赖项发生改变时才重新计算。
- React.memo() 是一个高阶组件,必须包裹组件才能使用,而 useMemo() 是一个 Hook,可以在函数组件中使用。综上所述,React.memo() 用于缓存组件的渲染结果,从而提高应用程序的性能,而 useMemo() 则用于缓存函数的计算结果,可以在函数组件中使用。
鱼友的精彩回答
悟道的回答
React.memo() 和 useMemo() 都是 React 中的性能优化工具,但是它们的用途和区别是不同的。
1、React.memo() React.memo() 是一个高阶组件,它可以帮助我们避免在不必要的情况下进行不必要的组件重新渲染。它的作用是对组件进行浅比较(shallow comparison)来判断是否需要重新渲染。如果组件的 props 没有发生变化,则 React.memo() 将会阻止组件重新渲染。React.memo() 可以接收一个可选的第二个参数,它是一个函数,用于比较新旧 props 是否相等。
示例:
import React from 'react';
const MyComponent = React.memo(props => {
return <div>{props.title}</div>;
});
2、useMemo() useMemo() 是一个 hook,它的作用是在渲染过程中缓存变量的值。useMemo() 接收两个参数,第一个参数是一个函数,用于计算缓存的值,第二个参数是一个数组,用于指定依赖项。如果依赖项发生变化,useMemo() 将重新计算缓存的值。如果依赖项没有变化,则 useMemo() 将返回之前缓存的值。
示例:
import React, { useMemo } from 'react';
const MyComponent = ({ list }) => {
const expensiveOperation = useMemo(() => {
// 计算复杂的操作
return list.map(item => item * 2);
}, [list]);
return <div>{expensiveOperation}</div>;
};
区别:
React.memo() 适用于优化组件的重新渲染,而 useMemo() 适用于缓存变量的值。React.memo() 通常用于优化组件性能,而 useMemo() 通常用于优化复杂计算的性能。此外,React.memo() 仅比较 props 是否相等,而 useMemo() 则可以根据依赖项进行计算,所以两者的应用场景也有所不同。
题目三
什么是 TypeScript 中的命名空间和模块?两者有什么区别?
官方解析
在 TypeScript 中,命名空间和模块都是用来组织和管理代码的方式。
命名空间提供了一种将代码划分为逻辑单元的方式,可以避免命名冲突。在命名空间内,所有变量、函数、类等都是私有的,需要使用 export 关键字进行导出,才能被其他代码使用。例如:
namespace MyNamespace {
export const PI = 3.14;
export function sayHello(name: string) {
console.log(`Hello, ${name}!`);
}
export class Person {
constructor(public name: string) {}
}
}
模块是用来组织和管理代码的方式,与命名空间类似,不同之处在于模块是按文件划分的,一个文件就是一个模块。模块可以使用 export 和 import 关键字来导出和导入代码。例如:
// moduleA.ts
export const PI = 3.14;
export function sayHello(name: string) {
console.log(`Hello, ${name}!`);
}
export class Person {
constructor(public name: string) {}
}
// moduleB.ts
import { PI, sayHello, Person } from './moduleA';
console.log(PI); // 3.14
sayHello('world'); // Hello, world!
const person = new Person('Alice');
console.log(person.name); // Alice
命名空间和模块的主要区别在于,命名空间是将代码划分为逻辑单元,而模块是按照文件划分的。在使用模块时,可以使用 import 和 export 进行代码的导入和导出,可以更方便地组织和管理代码。
鱼友的精彩回答
悟道的回答
在 TypeScript 中,命名空间(Namespace)和模块(Module)是两种不同的组织代码的方式。
命名空间是一种将相关的代码放在一个特定的命名空间下的方式,以避免名称冲突。可以使用 namespace 关键字来创建一个命名空间。
例如,下面是一个 Shapes 命名空间的示例,其中包含了三个形状的类定义:
namespace Shapes {
export class Circle {
// ...
}
export class Square {
// ...
}
export class Triangle {
// ...
}
}
模块是一种将代码组织成单独的文件,并且可以通过导入和导出来实现跨文件的代码共享的方式。可以使用 module 或 export 关键字来创建一个模块。
例如,下面是一个包含两个模块的示例:
// shape.ts
export interface Shape {
// ...
}
// circle.ts
import { Shape } from "./shape";
export class Circle implements Shape {
// ...
}
// main.ts
import { Circle } from "./circle";
let c = new Circle();
区别:
命名空间是一种在一个文件内组织代码的方式,而模块是一种跨文件组织代码的方式。因此,命名空间主要用于组织单个文件中的代码,而模块则主要用于跨文件共享代码。
命名空间可以通过嵌套来创建子命名空间,但模块没有这种方式。
命名空间的内部成员可以通过没有 export 关键字来隐藏,而模块中的所有成员都是公开的,需要通过 export 显式导出才能在其他模块中使用。
模块可以使用更灵活的导入和导出语法,例如按需导入和导出、重命名导入和导出等。而命名空间只能使用 namespace 和 import 语法来导入和导出。
星球活动
1.欢迎参与 ,搞定高频面试题,斩杀面试官!
2.欢迎已加入星球的同学 !
3.欢迎学习 ,手把手教你做出项目、写出高分简历!
加入我们
欢迎加入鱼皮的,鱼皮会 1 对 1 回答您的问题、直播带你做出项目、为你定制学习计划和求职指导,还能获取海量编程学习资源,和上万名学编程的同学共享知识、交流进步。
???? 加入星球后,您可以:
1)添加鱼皮本人微信,向他 1 对 1 提问,帮您解决问题、告别迷茫!
2)获取海量编程知识和资源,包括:3000+ 鱼皮的编程答疑和求职指导、原创编程学习路线、几十万字的编程学习知识库、几十 T 编程学习资源、500+ 精华帖等!

3)找鱼皮咨询求职建议和优化简历,次数不限!

4)鱼皮直播从 0 到 1 带大家做出项目,已有 50+ 直播、完结 3 套项目、10+ 项目分享,帮您掌握独立开发项目的能力、丰富简历!
外面一套项目课就上千元了,而星球内所有项目都有指导答疑,轻松解决问题
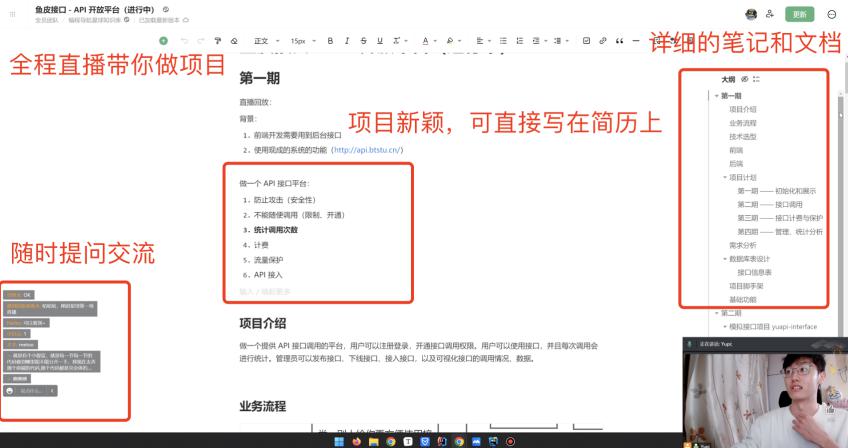
星球提供的所有服务,都是为了帮您更好地学编程、找到理想的工作。诚挚地欢迎您的加入,这可能是最好的学习机会,也是最值得的一笔投资!
长按扫码领优惠券加入,也可以添加微信 yupi1085 咨询星球(备注“想加星球”):

往期推荐