大家好呀,今天是的第十六天,一起来看看今天有哪些优质面试题吧。
后端
题目一
Dubbo 是什么?是否了解过它的架构设计?
官方解析
Dubbo 是一个高性能、轻量级的开源 Java RPC 框架,它提供了完整的 RPC 协议栈,包括服务发布、服务引用、负载均衡、容错、服务治理和服务监控等功能,同时提供了可扩展的 RPC 协议、数据模型、序列化和网络传输等组件,支持多语言和多协议。
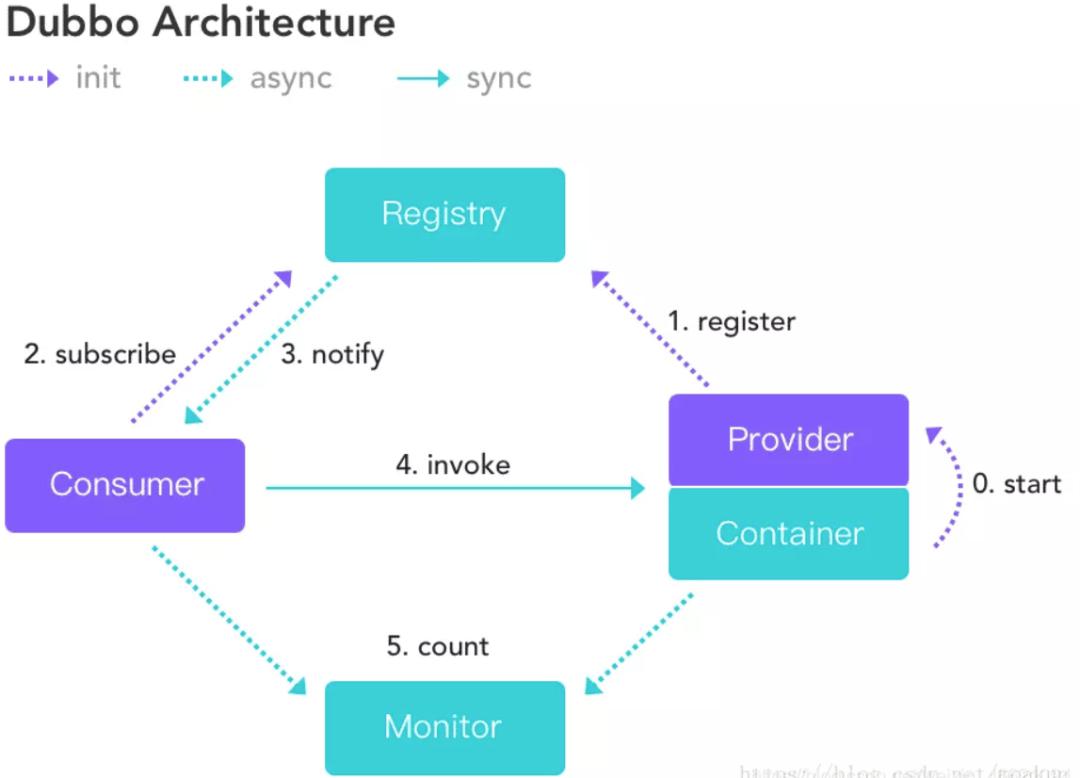
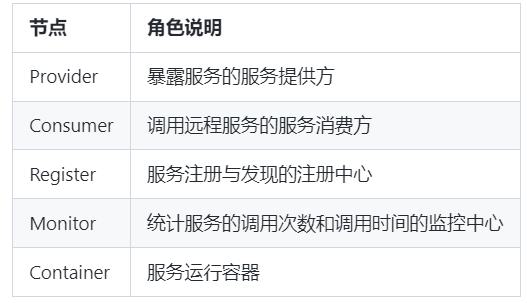
Dubbo 的架构设计主要包括服务提供者、服务消费者、注册中心和监控中心四个角色。其中,服务提供者提供服务的实现,并通过注册中心将自己注册到服务治理中心;服务消费者则通过注册中心发现可用的服务,并通过负载均衡策略选择一个服务提供者进行调用;注册中心主要负责服务的注册、发现和路由;监控中心则负责服务的统计和监控。
Dubbo 的架构设计采用了分层架构模式,将不同的功能模块进行分离,以达到模块化和可扩展的目的。同时,Dubbo 还提供了丰富的扩展点和插件机制,用户可以通过自定义扩展点和插件来满足不同的业务需求。
鱼皮补充:其实这道题的答案就在 dubbo 官方文档中,大家学 dubbo 的时候建议仔细阅读下官方文档
鱼友的精彩回答
Starry 的回答
Apache Dubbo 是一款高性能的 Java RPC 框架。其前身是阿里巴巴公司开源的一个高性能、轻量级的开源 Java RPC 框架,可以和 Spring 框架无缝集成。
什么是RPC?RPC 全称为 remote procedure call,即远程过程调用。
比如两台服务器 A 和 B,A 服务器上部署一个应用,B 服务器上部署一个应用,A 服务器上的应用想调用B 服务器上的应用提供的方法,由于两个应用不在一个内存空间,不能直接调用,所以需要通过网络来表达调用的语义和传达调用的数据。
Dubbo 架构图: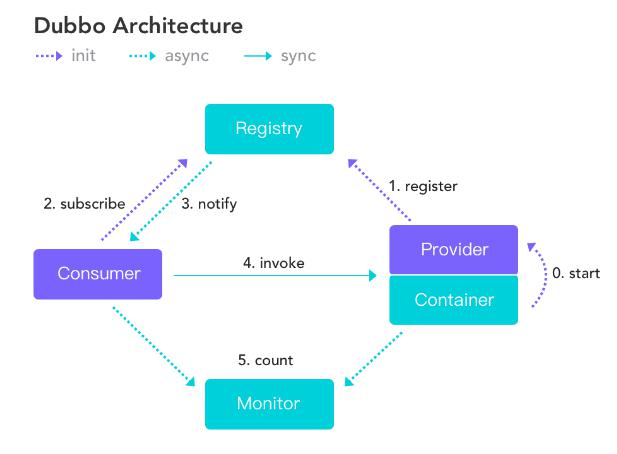 各节点角色说明:
各节点角色说明: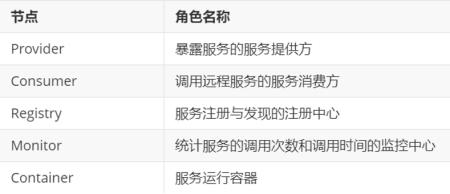 调用关系说明:
调用关系说明:维萨斯的回答
Apahce 提供的 RPC 框架,前身是 alibaba。
( 这一点重要也不重要 )
重要: 因为实际开发中如果版本没控制好( 点名 SpringBoot 较新版本和 alibaba 的旧 Dubbo ),容易报一些莫名奇妙的错误。
不重要:Dubbo 现在已经到 3.x 系列,现在大家用 Apache 的 Dubbo3.x 系列基本不会出现版本问题
分为 服务治理控制面 + Dubbo 数据面(图一是现在官方给的图
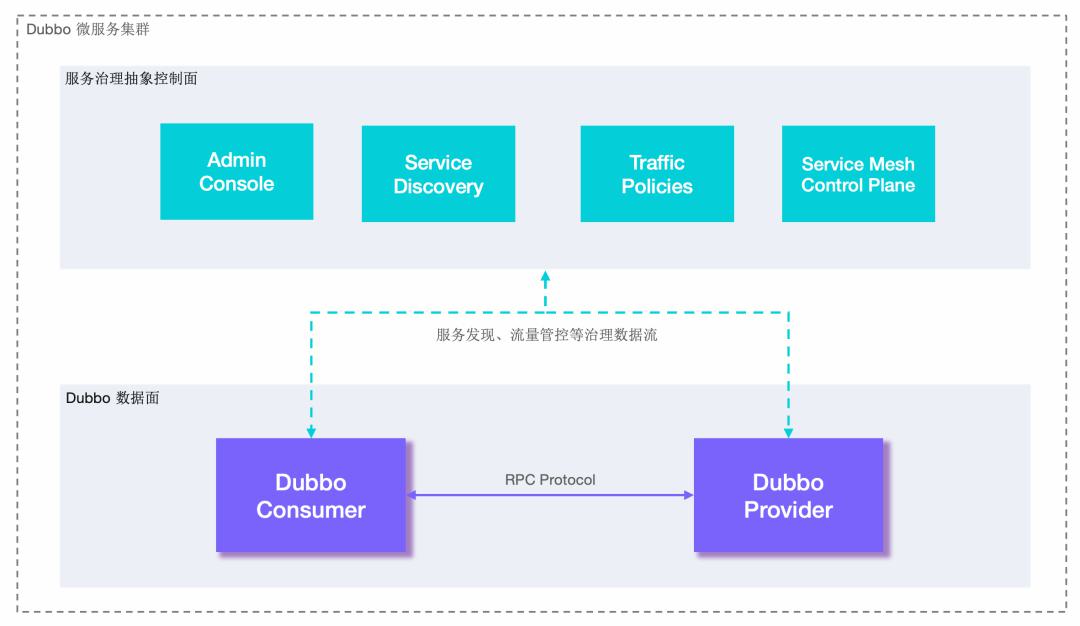
在服务控制面:
- 包含协调服务发现的注册中心、流量管控策略、Dubbo Admin 控制台、负载均衡等一系列的实现
在 Dubbo 数据面:
- 约束了微服务定义、开发与调用的规范,定义了服务治理流程及适配模式 作为 RPC 通信协议实现 解决服务间数据传输的编解码问题
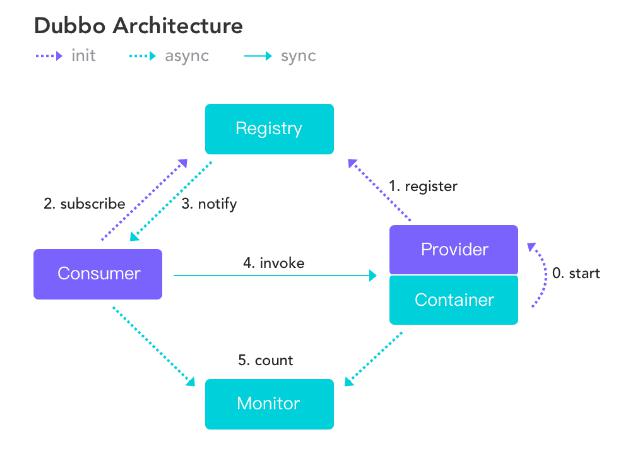
感觉新的太抽象了,还是以前的 Dubbo 框架图典中典
HeiHei 的回答
Dubbo 是一种基于 Java 语言的高性能分布式服务框架,用于简化不同系统之间的通信和协调。它可以帮助用户构建高性能、可扩展、可靠的RPC服务,并支持多种传输协议、负载均衡、服务路由、服务治理、服务监控等功能
架构设计从分层理解: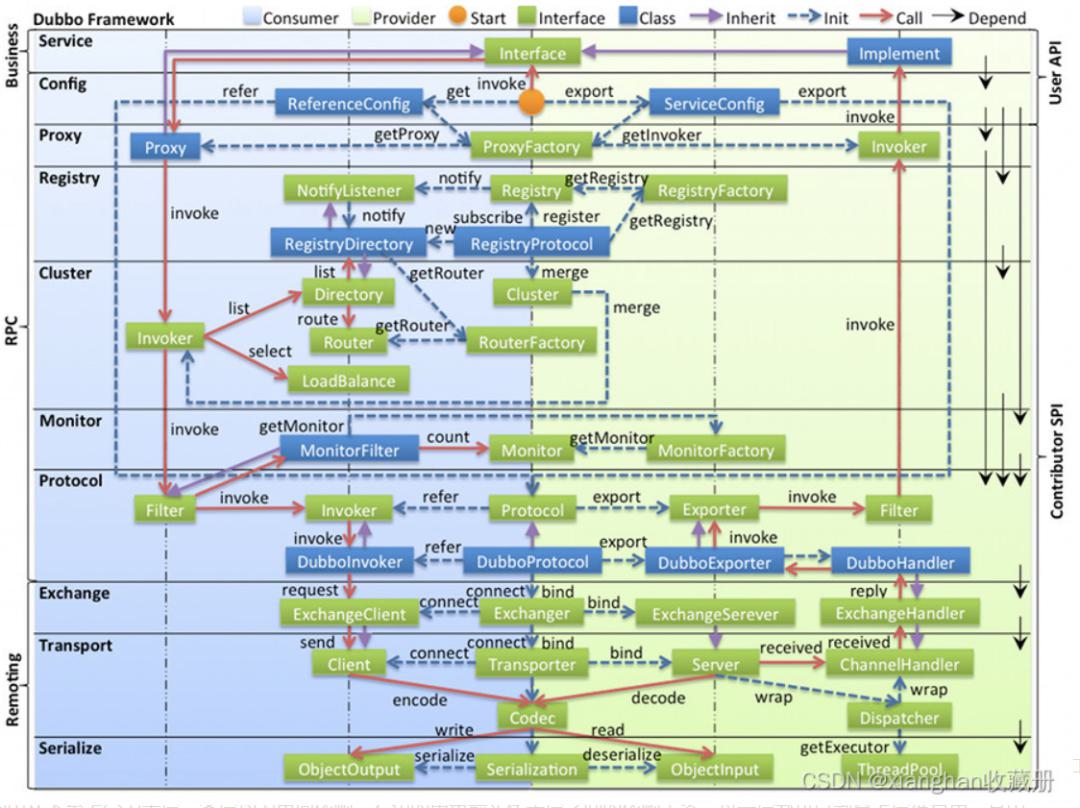
Dubbo 的整体架构可以分为三层:业务层、RPC 层、Remoting 层
接口服务层(Service):与业务逻辑相关,根据 provider 和 consumer 的业务设计对应的接口和实现。
配置层(Config):用来初始化配置信息,用来管理Dubbo的配置。
服务代理层(Proxy):服务接口透明代理,provider和consumer都会生成Proxy,它用来调用远程接口。生成服务的客户端Stub和服务端的Skeleton,以ServiceProxy为中心,扩展接口为ProxyFactory。
服务注册层(Registry):封装服务地址的注册和发现,以URL为中心,扩展接口为RegistryFactory、Resitry、RegistryService。
路由层(Cluster):封装多个提供者的路由和负载均衡,并桥接注册中心,扩展接口为 Cluster、Directory、Router 和 LoadBlancce。
监控层(Monitor):PRC调用次数和调用时间监控,以Statistics为中心,扩展接口为 MonitorFactory、Monitor 和 MonitorService。
远程调用层(Protocol):封装RPC调用的具体过程,以 Invocation 和 Result 为中心,扩展接口为 Protocal、Invoker 和 Exporter。
信息交换层(Exchange):封装请求响应模式,同步转异步,以 Request 和Response 为中心,扩展接口为 Exchanger、ExchangeChannel、ExchangeClient 和 ExchangeServer。
网络传输层(Transport):将网络传输封装成统一接口,可以在这之上扩展更多的网络传输方式,扩展接口为 Channel、Transporter、Client、Server 和 Codec。 10.数据序列层(Serialize): 负责网络传输的序列化和反序列化,扩展接口为 Serialization、ObjectInput、ObjectOutput 和 ThreadPool。
Dubbo的架构设计主要包括服务提供者、服务消费者、注册中心和监控中心四个角色。其中,服务提供者提供服务的实现,并通过注册中心将自己注册到服务治理中心;服务消费者则通过注册中心发现可用的服务,并通过负载均衡策略选择一个服务提供者进行调用;注册中心主要负责服务的注册、发现和路由;监控中心则负责服务的统计和监控。
题目二
synchronized 关键字是什么,有什么作用?
官方解析
synchronized 是 Java 中的一个关键字,用于实现线程同步。具体来说,synchronized 用于修饰方法或代码块,使得同一时刻只能有一个线程访问被修饰的代码,其他线程需要等待当前线程执行完毕后才能访问。
synchronized 主要用于解决多线程并发访问共享资源时出现的线程安全问题。
如果多个线程同时访问一个共享资源,就会出现多个线程同时修改这个资源的情况,从而导致数据不一致等问题。而使用 synchronized 可以保证同一时刻只有一个线程访问该资源,从而避免了线程安全问题。
synchronized 的作用不仅限于线程同步,它还可以保证可见性和有序性,即保证在同一个锁上,一个线程修改了共享变量的值之后,另一个线程能够立即看到修改后的值,并且在多个线程执行顺序上保证了一致性。
需要注意的是,使用 synchronized 会带来一定的性能损失,因为每次进入同步块时都需要获得锁,这会增加线程的等待时间和上下文切换的开销。同时,如果同步块的代码执行时间很短,也会增加不必要的性能开销。因此,需要根据具体情况来判断是否需要使用 synchronized。
鱼皮补充:这题如果能再延伸回答一下 synchronized 的实现机制(锁升级),会更好
鱼友的精彩回答
猿二哈的回答
synchronize 关键字的作用
synchronize 是一个解决并发安全的的修饰关键字
synchronize 可以保证操作的原子性与可见性
synchronize可以加在方法上,表示在多线程的情况下,只有一个线程可以访问这个方法
如果一个对象有多个synchronize 方法,一个线程访问了这个对象的一个 synchronize 方法,其他线程就不能访问这个对象的任何一个 synchronize 方法
多个不同实例对象的 synchronize 方法之间没有关系
synchronize 可以加在代码块上,在多线程的情况下,如果一个线程访问了这个代码块,其他线程就无法访问这个对象的任何一个 synchronize 方法
synchronize 锁 class,表示这个 synchronize 方法对这个类的所有实例都有效,类 static 的类全局效果
关键词:并发安全,原子性,可见性,加方法,加代码块,加 class
CodeJuzi 的回答
synchronized 是 Java 中的一个关键字,用来实现同步锁。
它可以修饰方法或代码块,保证同一时刻只有一个线程可以执行被修饰的部分
synchronized 的作用有以下几点:
- 保证数据的原子性和可见性,防止多线程操作导致的数据不一致。
- 防止指令重排序,保证代码执行的顺序和预期一致。
- 实现线程间的通信,通过 wait 和 notify 方法来实现线程的等待和唤醒。
synchronized的使用方式有以下几种:
- 修饰非静态方法,锁对象是当前实例对象
- 修饰静态方法,锁对象是当前类对象
- 修饰代码块,锁对象是括号里指定的对象
synchronized 和其他同步工具(如 ReentrantLock)相比,有以下优缺点:
- 优点:简单易用,不需要手动释放锁。
- 缺点:不灵活,不能设置超时时间、中断等;效率低,每次都要进入内核态获取锁;不可重入,同一个线程在获取到锁后还要再次获取锁会造成死锁
回家养猪的回答
说一说自己对于 synchronized 关键字的了解synchronized 关键字解决的是多个线程之间访问资源的同步性,synchronized 关键字可以保证被它修饰的方法或者代码块在任意时刻只能有一个线程执行
在 Java 早期版本中, synchronized 属于重量级锁,效率低下,因为锁监视器(monitor)是依赖于底层的操作系统来实现的。如果要挂起或者唤醒一个线程,都需要操作系统帮忙完成,而操作系统实现线程之间的切换时需要从用户态转换到内核态,这个状态之间的转换需要相对比较长的时间,这也是为什么早期的 synchronized 效率低的原因。
Java 官方对从 JVM 层面对 synchronized 较大优化,如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销。所以现在的 synchronized 锁效率也优化得很不错了。
说说自己是怎么使用 synchronized 关键字修饰非静态方法, 锁的是 this(当前对象), 也就是一个对象用一把锁
修饰静态方法, 锁的是 类.class , 也就是类的所有对象公用一把锁
修饰代码块
尽量不要使用 synchronized(String a) 因为 JVM 中,字符串常量池具有缓存功能
synchronized原理synchronized 同步语句块的实现使用的是 monitorenter 和 monitorexit 指令,其中 monitorenter 指令指向同步代码块的开始位置, monitorexit 指令则指明同步代码块的结束位置
当多个线程同时访问该方法,那么这些线程会先被放进对象的锁池,此时线程处于 blocking 状态
当一个线程获取到了实例对象的监视器(monitor)锁,那么就可以进入 running 状态,执行方法,此时 lock record 中的 owner 设置为当前线程,count 加 1 表示当前对象锁被一个线程获取
当 running 状态的线程调用wait()方法,那么当前线程释放 monitor 对象,进入 waiting 状态, lock record 中的 owner 变为 null,count 减 1,同时线程进入等待池,直到有线程调用 notify() 方法唤醒该线程,则该线程重新获取 monitor 对象进入 owner
如果当前线程执行完毕,那么也释放 monitor 对象,进入 waiting 状态,lock record 中的 owner 变为null,count 减 1
JDK1.6 之后的 synchronized 底层做了哪些优化?java 的线程模型是 1 对 1 的, 加锁需要调用操作系统的底层原语 mutex, 所以每次切换线程都需要操作系统切换到内核态, 开销很大. 这也是之前 synchronized的问题所在, jdk1.6 对其进行了优化, 从无锁到偏向锁到轻量级锁到重量级锁 自旋锁就不需要阻塞, 也就不需要操作系统切换为内核态去做, 所以短时间的自旋开销是比较低的.
JDK 1.6 引入了偏向锁和轻量级锁,从而让锁拥有了四个状态:无锁状态(unlocked)、偏向锁状态(biasble)、轻量级锁状态(lightweight locked)和重量级锁状态(inflated)。
虚拟机对象头里锁标志位, 就记录了这4中状态.
偏向锁大多数时候是不存在锁竞争的,常常是一个线程多次获得同一个锁,因此如果每次都要竞争锁会增大很多没有必要付出的代价,为了降低获取锁的代价,才引入的偏向锁。
当锁对象第一次被线程获得的时候,使用 CAS 操作将线程 ID 记录到对象头的 MarkWord 中,这个线程以后每次进入这个锁相关的同步块就不需要再进行任何同步操作。
当有另外一个线程去尝试获取这个锁对象时,偏向状态就宣告结束,此时撤销偏向后恢复到未锁定状态或者轻量级锁状态。
轻量级锁轻量级锁考虑的是竞争锁对象的线程不多,而且线程持有锁的时间也不长的情景。因为阻塞线程需要 CPU 从用户态转到内核态,代价较大,如果刚刚阻塞不久这个锁就被释放了,那这个代价就有点得不偿失了,因此这个时候就干脆不阻塞这个线程,让它自旋这等待锁释放。
轻量级锁是相对于传统的重量级锁而言,它使用自旋 + CAS 操作来避免重量级锁使用互斥量的开销。
长时间的自旋会使 CPU 一直空转, 浪费 CPU, 所以这里自旋是适应性自旋, 自旋时间由上一个线程自旋的时间决定的.
线程自旋的次数到了阈值, 另外一个线程还没释放锁, 那么就膨胀为重量级锁。
如果有两条以上的线程争用同一个锁,那轻量级锁就不再有效,要膨胀为重量级锁。
锁消除锁消除是指对于被检测出不可能存在竞争的共享数据的锁进行消除。
锁消除主要是通过逃逸分析来支持,如果堆上的共享数据不可能逃逸出去被其它线程访问到,那么就可以把它们当成私有数据对待,也就可以将它们的锁进行消除。
锁粗化如果一系列的连续操作都对同一个对象反复加锁和解锁,频繁的加锁操作就会导致性能损耗。
比如连续使用 StringBuffer 的 append() 方法就属于这类情况。如果虚拟机探测到由这样的一串零碎的操作都对同一个对象加锁,将会把加锁的范围扩展(粗化)到整个操作序列的外部, 这样只需要加锁一次就可以了。
题目三
如何设计一个点赞系统?
官方解析
设计一个点赞系统可以分为以下几个步骤:
确定需求:需要明确点赞的对象是什么,是否需要计数等信息,同时需要考虑点赞的业务场景,如用户点赞、文章点赞等。
数据库设计:需要设计点赞相关的数据表,可以包含点赞者 ID、被点赞对象 ID、点赞时间等字段。
接口设计:需要设计点赞相关的接口,包括点赞、取消点赞、查询点赞数等操作。
业务逻辑实现:在接口中实现点赞相关的业务逻辑,包括判断点赞状态、更新点赞数、更新点赞状态等操作。
安全性考虑:需要考虑并发访问的情况,可以使用分布式锁来保证数据一致性和安全性。
性能优化:如果点赞系统的访问量很高,可以使用缓存来提高性能,比如使用 Redis 来缓存点赞数等信息。
监控和日志:需要对点赞系统进行监控和日志记录,以便及时发现和排查问题。
总之,设计一个点赞系统需要综合考虑需求、数据库设计、接口设计、业务逻辑实现、安全性、性能优化等方面,同时需要不断优化和完善。
鱼皮补充:题解中的最后一句话是很关键的,大家在回答时,首先要明确实际的业务场景,比如这个系统同时有多少人使用、日均点赞量多少等,再去考虑用 MySQL、还是 Redis、甚至是 MQ 来实现。
鱼友的精彩回答
Ming 的回答
如何设计一个点赞系统?从需求上分析
- 点赞类别:帖子、评论、or 其他
- 点赞限制
- 仅登录用户还是游客都可以点赞?
- 可以无限点赞还是每个用户仅限点1次?
- 点赞是否通知用户
- 通知频率:每次点赞都通知 1 次,还是满 5 次合并通知 1 次
- 通知样式:点赞帖子和点赞评论,通知的内容要怎么区分显示
从数据库设计上
- 点赞数量:是单独一张表?还是在帖子表直接加一个字段?
- (前者的好处是,这样如果例如有其他类别的内容需要加点赞功能,就不用再修改数据库,后者的好处是后台统计功能方便查数据,不需要查两张表)
- 点赞记录表:记录点赞操作记录,哪个用户点赞了哪个帖子
从性能考虑上
- 点赞是个高频操作,肯定不能每次都直接操作数据库,需要加一层缓存
- 是单独独立一个key,如 {post_id}_like_num 记录
- 还是随着跟其他数量字段,一起构造一个key 如 {post_info}_num 一个hash字段
- 这里的设计会影响如何保持数据库和缓存一致性的问题
一致性考虑
- 看是否需要强一致性,如果不需要的话,就不需要加锁,这样可以减轻实现负担和提高一定的系统性能
就大概以上是我觉得比较重要,需要考虑的地方,然后编码实现上其实大差不差,主要还是要根据需求以及后续可拓展性去考虑
前端
题目一
什么是箭头函数?能使用 new 来创建箭头函数么?
官方解析
箭头函数是 ES6 中新增的一种函数定义方式,可以用来简化函数的定义和书写。箭头函数的特点是:简洁的语法、绑定 this 关键字、不能用作构造函数。
箭头函数使用箭头(=>)来定义,基本语法如下:
(parameters) => { statements }
其中,parameters 是函数的参数列表,可以是一个或多个参数,多个参数之间用逗号分隔;statements 是函数的执行语句,可以是一个或多个语句,多个语句之间用花括号包裹起来。
在箭头函数中,this 关键字指向的是函数定义时所在的对象,而不是执行时所在的对象。这个特性有助于避免 this 的指向问题,使得代码更加简洁易读。
需要注意的是,箭头函数不能用作构造函数,也就是不能通过 new 关键字来创建实例。因为箭头函数没有自己的 this,而是继承了外层作用域的 this。如果用 new 来创建实例,就会出现意料之外的结果。
鱼皮补充:”在箭头函数中,this 关键字指向的是函数定义时所在的对象,而不是执行时所在的对象。这个特性有助于避免 this 的指向问题,使得代码更加简洁易读” —— 这句话很关键
鱼友的精彩回答
你还费解吗的回答
箭头函数的介绍箭头函数是 ES6 新增的一种使用“箭头“(=>)定义函数的方法,可以简化函数表达式的结构,写出更加简洁的代码。箭头函数的基本使用方法如下:
如果函数没有参数或有多个参数,则直接使用一个小括号"()"代表参数部分;如果只有一个参数,可以省略小括号:
let f = () => { return 1 + 2; }; // 没有参数
let f = (a, b) => { return a + b; }; // 有多个参数
let f = x = > { return x * 2; }; // 只有一个参数,括号可有可无
如果函数体只有一行代码,比如一个赋值操作、一条表达式、调用另一个函数、一条输出语句等,则可以省略函数体的大括号“{}”,调用函数会隐式返回这行代码的值;如果只是想执行一行代码,不需要返回值,则可以在代码前加上 void 关键字:
// 赋值操作
let f = x => x = 1;
let res = f(); // 无论是否传参,调用f时都会先执行赋值操作(x = 1),再把x的值作为函数的返回值返回
console.log(res); // 1
// 表达式
let f = x => x * 2;
console.log(f(2)); // 4
// 调用另一个函数
let fn = function () {};
let f = () => fn();
console.log(f()); // "undefined"
// 只执行一行代码,无需返回值
let f = () => void (1 + 2);
console.log(f()); // ”undefined“
注意,由于大括号会被解释为代码块,所以如果箭头函数直接返回一个对象,必须在对象外加上一个小括号,否则会报错:
let getTempItem = id => { id: id, name: "Temp" }; // 报错
let getTempItem = id => ({ id: id, name: "Temp" }); // 不报错
// 特殊情况
let foo = () => { a: 1 };
foo() // undefined
对于上述的特殊情况,原意是返回一个对象 { a: 1 },但是由于引擎认为大括号是代码块,所以执行了一行语句 a: 1。这时,a 可以被解释为语句的标签,因此实际执行的语句是 1;,然后函数就结束了,没有返回值。
与变量的解构赋值结合使用:
function full(person) {
return person.first + ' ' + person.last;
}
// 可简化为:
const full = ({ first, last }) => first + ' ' + last;
简化回调函数:
[1,2,3].map(function (x) {
return x * x;
});
// 可简化为:
[1,2,3].map(x => x * x);
箭头函数的缺陷尽管箭头函数为函数的定义带来了便利,但相比于普通函数,它存在几个缺陷:
没有 this:
对于普通函数来说,内部的 this 指向函数运行时所在的对象,而对于箭头函数来说,它没有自己的 this 对象,当在其内部访问 this 时,会沿着作用域链查找 this 的值。这就意味着,如果箭头函数被一层或多层非箭头函数包含,则 this 会指向最近一层非箭头函数的 this。也就是说,箭头函数的 this 在编写代码的时候就已经确定了,不会随代码的运行而发生改变。另外,由于箭头函数没有自己的this,所以也就不能用 call()、apply()、bind() 这些方法去改变 this 的指向。
没有原型、super、new.target:之所以设计箭头函数,仅仅是为了实现一种简洁的函数定义语法,无需考虑与函数(对象)相关的东西,所以箭头函数没有原型,即没有 prototype 属性,也没有相关的 super、new.target 等。
没有 arguments:箭头函数没有自己的 arguments 对象,所以无法通过它获取参数。如果要获取,可以用 rest 参数代替:let arguments = (...args) => args;。注意,与 this、 super、new.target 一样,arguments 的值由最近一层非箭头函数决定,比如:
function f() {
setTimeout(() => {
console.log('args:', arguments);
}, 100);
}
f(1, 2, 3) // args: [1, 2, 3]
不能通过 new 关键字调用:JS 的函数有两个内部方法:[[Call]] 和 [[Construct]]。当通过 new 调用普通函数时,执行 [[Construct]] 方法,创建一个实例对象,然后再执行函数体,将 this 绑定到实例上。当直接调用的时候,执行 [[Call]] 方法,直接执行函数体。而由于箭头函数并没有 [[Construct]] 方法,不能被用作构造函数,如果通过 new 的方式调用,会报错:
let F = () => {};
new F(); // Uncaught TypeError: f is not a constructor
mos 的回答1. 相比普通函数,箭头函数有更加简洁的语法。普通函数
function add(num) {
return num + 10
}
箭头函数
const add = num => num + 10;
箭头函数是 ES6 中新增的一种函数定义方式,可以用来简化函数的定义和书写。箭头函数的特点是:简洁的语法、绑定 this 关键字、不能用作构造函数。
箭头函数使用箭头(=>)来定义,基本语法如下:
(parameters) => { statements }
其中,parameters 是函数的参数列表,可以是一个或多个参数,多个参数之间用逗号分隔;statements 是函数的执行语句,可以是一个或多个语句,多个语句之间用花括号包裹起来。
2. 箭头函数不绑定this,会捕获其所在上下文的this,作为自己的this。箭头函数的外层如果有普通函数,那么箭头函数的this就是这个外层的普通函数的this,箭头函数的外层如果没有普通函数,那么箭头函数的this就是全局变量. 下面这个例子是箭头函数的外层有普通函数。
let obj = {
fn:function(){
console.log('我是普通函数',this === obj) // true
return ()=>{
console.log('我是箭头函数',this === obj) // true
}
}
}
console.log(obj.fn()())
下面这个例子是箭头函数的外层没有普通函数。
let obj = {
fn:()=>{
console.log(this === window);
}
}
console.log(obj.fn())// true
箭头函数是匿名函数,不能作为构造函数,不可以使用new命令,否则后抛出错误。 需要注意的是,箭头函数不能用作构造函数,也就是不能通过 new 关键字来创建实例。因为箭头函数没有自己的 this,而是继承了外层作用域的 this。如果用 new 来创建实例,就会出现意料之外的结果。
4. 箭头函数不绑定arguments,取而代之用rest参数解决,同时没有super和new.target。箭头函数没有arguments、super、new.target的绑定,这些值由外围最近一层非箭头函数决定。
下面的这个函数会报错,在浏览器环境下。
let f = ()=>console.log(arguments);
//报错
f(); // arguments is not defined
下面的箭头函数不会报错,因为 arguments 是外围函数的。
function fn(){
let f = ()=> {
console.log(arguments)
}
f();
}
fn(1,2,3) // [1,2,3]
箭头函数可以通过拓展运算符获取传入的参数。
const testFunc = (...args) => {
console.log(args);
}
testFunc([1,2,3])//[ [ 1, 2, 3 ] ]
5. 使用call,apply,bind并不会改变箭头函数中的this指向。当对箭头函数使用call或apply方法时,只会传入参数并调用函数,并不会改变箭头函数中this的指向。 当对箭头函数使用bind方法时,只会返回一个预设参数的新函数,并不会改变这个新函数的this指向。
请看下面的代码
window.name = "window_name";
let f1 = function () {
return this.name;
};
let f2 = () => this.name;
let obj = { name: "obj_name" };
console.log(f1.call(obj)); // obj_name
console.log(f2.call(obj)); // window_name
console.log(f1.apply(obj)); // obj_name
console.log(f2.apply(obj)); // window_name
console.log(f1.bind(obj)()); // obj_name
console.log(f2.bind(obj)()); // window_name
6. 箭头函数没有原型对象prototype这个属性由于不可以通过new关键字调用,所以没有构建原型的需求,所以箭头函数没有prototype这个属性。
let F = ()=>{};
console.log(F.prototype) // undefined
题目二
什么是 webpack 的热更新?它的实现原理是什么?
官方解析
webpack 的热更新(Hot Module Replacement,简称 HMR)是一种开发时提高开发效率的技术,可以实现无需刷新页面即可看到代码修改后的效果。在使用 HMR 后,当修改了代码后,webpack 只会重新编译修改的代码,并将新的模块发送到客户端,替换掉旧的模块,从而达到实时更新页面的目的。
实现 HMR 的关键是在客户端和服务器端之间建立一个 WebSocket 连接,当代码发生变化时,服务器端会将新的模块发送给客户端,客户端接收到新的模块后会用新模块替换旧模块,从而实现实时更新。
具体来说,webpack HMR 主要分为以下几个步骤:
总之,HMR 可以大大提高开发效率,同时也能够减少代码变更时的刷新操作,提高开发体验。
鱼友的精彩回答
antlu1 的回答
Webpack 热更新:热更新(HMR)全程Hot Module Replacement,可以理解为模块热替换,指在应用程序运行的过程中,替换、添加、删除模块,而无需重新刷新整个应用。
例如在运行过程中修改了某个模块,通过自动刷新会导致整个应用的整体刷新,那页面中的状态信息都会丢失;如果使用的是HMR,就可以实现只将修改的模块实时替换至应用中,不必完全刷新应用。
实现原理:1.第⼀步,在 webpack 的 watch 模式下,⽂件系统中某⼀个⽂件发⽣修改,webpack 监听到⽂件变化,根据配置⽂件对模块重新编译打包,并将打包后的代码通过简单的 JavaScript 对象保存在内存中。
2.第⼆步是 webpack-dev-server 和 webpack 之间的接⼝交互,⽽在这⼀步,主要是 dev-server 的中间件 webpack- dev-middleware 和webpack 之间的交互,webpack-dev-middleware 调⽤ webpack 暴露的 API对代码变化进⾏监 控,并且告诉 webpack,将代码打包到内存中。
3.第三步是 webpack-dev-server 对⽂件变化的⼀个监控,这⼀步不同于第⼀步,并不是监控代码变化重新打包。当我们在配置⽂件中配置了devServer.watchContentBase 为 true 的时候,Server 会监听这些配置⽂件夹中静态⽂件的变化,变化后会通知浏览器端对应⽤进⾏ live reload。注意,这⼉是浏览器刷新,和 HMR 是两个概念。
4.第四步也是 webpack-dev-server 代码的⼯作,该步骤主要是通过 sockjs(webpack-dev-server 的依赖)在浏览器端和服务端之间建⽴⼀个 websocket ⻓连接,将 webpack 编译打包的各个阶段的状态信息告知浏览器端,同时也包括第三步中 Server 监听静态⽂件变化的信息。浏览器端根据这些 socket 消息进⾏不同的操作。当然服务端传递的最主要信息还是新模块的 hash 值,后⾯的步骤根据这⼀ hash 值来进⾏模块热替换。
5.webpack-dev-server/client 端并不能够请求更新的代码,也不会执⾏热更模块操作,⽽把这些⼯作⼜交回给了webpack,webpack/hot/dev-server 的⼯作就是根据 webpack-dev-server/client 传给它的信息以及 dev-server 的配置决定是刷新浏览器呢还是进⾏模块热更新。当然如果仅仅是刷新浏览器,也就没有后⾯那些步骤了。
6.HotModuleReplacement.runtime 是客户端 HMR 的中枢,它接收到上⼀步传递给他的新模块的 hash 值,它通过JsonpMainTemplate.runtime 向 server 端发送 Ajax 请求,服务端返回⼀个 json,该 json 包含了所有要更新的模块的 hash 值,获取到更新列表后,该模块再次通过 jsonp 请求,获取到最新的模块代码。这就是上图中 7、8、9 步骤。
7.⽽第 10 步是决定 HMR 成功与否的关键步骤,在该步骤中,HotModulePlugin 将会对新旧模块进⾏对⽐,决定是否更新模块,在决定更新模块后,检查模块之间的依赖关系,更新模块的同时更新模块间的依赖引⽤。
8.最后⼀步,当 HMR 失败后,回退到 live reload 操作,也就是进⾏浏览器刷新来获取最新打包代码
题目三
说说常规的前端性能优化手段
官方解析
前端性能优化是一个重要的工作,可以有效地提升用户的体验和网站的访问速度。以下是一些常规的前端性能优化手段:
- 减少 HTTP 请求:合并文件、使用 CSS 精灵、减小图片大小等。
- 压缩文件:使用压缩工具压缩 HTML、CSS、JavaScript、图片等文件大小。
- 缓存:使用缓存来减少网络请求。
- 懒加载:图片或者资源在真正需要的时候再加载,可以有效减少页面加载时间。
- 静态资源 CDN 加速:利用 CDN 分发静态资源,减少服务器压力,提高网站的访问速度。
- 减少 DOM 操作:DOM 操作是很耗费性能的,所以要尽量减少 DOM 操作的次数,尽量使用批量操作。
- 使用 CSS3 动画:使用 CSS3 动画而不是 JavaScript 动画,因为 CSS3 动画的性能更优。
- 使用字体图标:使用字体图标可以减少图片的请求,提高页面性能。
- 去除不必要的插件:移除不必要的插件可以提高页面加载速度,减少不必要的代码。
- 图片优化:对图片进行压缩和优化,减少图片的大小和请求次数。
以上是一些常规的前端性能优化手段,可以根据实际项目情况选择适合的优化手段来提高页面性能。
鱼皮补充:建议大家在上线网站后,可以尝试一下性能优化,并且学习下网站性能的分析工具的用法,得到明确的性能优化数据,比如网页首屏渲染时间由 2 s 优化为 1.1 s
鱼友的精彩回答
你还费解吗的回答
常见的前端性能优化手段有以下几种:
DNS 优化:避免浏览器并发数限制,将HTML/CSS/JS,jpg/png,api 接口等不同资源放在不同域名下,从而减少DNS的请求次数;DNS 预解析。
CDN 回源:回源指浏览器访问CDN集群上静态文件时,文件缓存过期,直接穿透 CDN 集群而访问源站机器的行为。
浏览器缓存优化:IndexDB、cookie、localStorage、sessionstorage。
HTML5 离线化:通过选用不同的离线包类型
全局离线包:包含公共的资源,可供多个应用共同使用
私有离线包:只可以被某个应用单独使用
接口优化:
- 接口合并:减少http请求
- 接口上 CDN:把不需要实时更新的接口同步到CDN,如果接口数据更新再重新同步 CDN
- 接口域名上 CDN:增强可用性,稳定性
- 合理使用缓存:异步接口数据优先使用本地 localstorage 中的缓存数据,通过 md5 判断是否需要数据更新
页面加载策略优化:
- 网络请求优化:减少网络资源的请求和加载耗时
- 预加载
- 开启GZIP
- 预渲染:可以让浏览器提前加载指定页面的所有资源。
- 使用 HTTP/2、HTTP/3提升资源请求速度
- 资源请求合并,减少http请求
- 合理使用defer,async
- 首屏加载优化
- 对页面内容进行分片/分屏加载
- 懒加载:监听scroll事件;使用IntersectionObserver
- 首屏只加载需要的资源,对于不需要的资源不加载。
- 客户端离线包方案
- 客户端进行预请求和预加载
- 渲染过程优化:减少用户操作等待时间
- 按需加载
- 减少回流和重绘
- 减少/合并dom操作,减少浏览器的计算损耗
- 浏览器运算逻辑优化
- 拆解长任务,避免出现长时间计算导致页面卡顿
- 提前将计算结果缓存
- 关键渲染路径优化:关键渲染路径是指浏览器将HTML,CSS,JavaScript转换为屏幕上所呈现的实际像素这期间所经历的一系列步骤。
- CSS 的 <link> 标签放在 <head></head> 之间
- <script> 标签放在 </body> 之前
页面静态化(SSR)
图片优化:选择合适的图片格式。
HTML代码优化:
- 精简HTML代码:减少HTML的嵌套;减少DOM节点数;减少无语义代码;删除多余的空格、换行符、缩进等等
- 文件放在合适位置:CSS 样式文件链接尽量放在页面头部;JS 放在HTML底部CSS 代码优化:
- 提升文件加载性能:使用外链的 CSS;尽量避免使用 @import,@import影响css文件的加载速度
- 精简 CSS 代码:利用CSS继承减少代码量;避免使用复杂的选择器,层级越少越好字体文件优化:
- 使用cdn加载字体文件
- 开启gzip压缩字体文件
- 通过font-display来调整加载顺序
- 字体裁剪,剔除不需要使用到的字体
- 内联字体JS 代码优化:
- 提升 JS 文件加载性能:JS 文件放在body 底部;合并js文件;合理使用defer和async
- JS 变量和函数优化:尽量使用 id 选择器;尽量避免使用 eval;js 函数尽可能保持整洁;使用节流、防抖函数;使用事件委托
- JS 动画优化:避免添加大量 js 动画;尽量使用 css3 动画;尽量使用 Canvas 动画;使用 requestAnimationFrame 代替 settimeout 和 setinterval。
webpack 打包优化
禾木的回答
一、页面级优化 1、减少HTTP请求数 2、避免重复的资源请求 3、减少cookie传输 4、Lazy Load 5、将CSS放在HEAD中 6、将外部脚本置底 7、减少重定向 8、异步请求Callback 9、使用CDN 10、使用反向代理 二、代码级优化 1、减少DOM操作 2、慎用with 3、避免使用eval和Function 4、减少作用域链查找 5、数据访问 6、字符串拼接 7、CSS选择符优化
星球活动
1.欢迎参与 ,搞定高频面试题,斩杀面试官!
2.欢迎已加入星球的同学 !
3.欢迎学习 ,手把手教你做出项目、写出高分简历!
加入我们
欢迎加入鱼皮的,鱼皮会 1 对 1 回答您的问题、直播带你做出项目、为你定制学习计划和求职指导,还能获取海量编程学习资源,和上万名学编程的同学共享知识、交流进步。
???? 加入星球后,您可以:
1)添加鱼皮本人微信,向他 1 对 1 提问,帮您解决问题、告别迷茫!
2)获取海量编程知识和资源,包括:3000+ 鱼皮的编程答疑和求职指导、原创编程学习路线、几十万字的编程学习知识库、几十 T 编程学习资源、500+ 精华帖等!

3)找鱼皮咨询求职建议和优化简历,次数不限!

4)鱼皮直播从 0 到 1 带大家做出项目,已有 50+ 直播、完结 3 套项目、10+ 项目分享,帮您掌握独立开发项目的能力、丰富简历!
外面一套项目课就上千元了,而星球内所有项目都有指导答疑,轻松解决问题
星球提供的所有服务,都是为了帮您更好地学编程、找到理想的工作。诚挚地欢迎您的加入,这可能是最好的学习机会,也是最值得的一笔投资!
长按扫码领优惠券加入,也可以添加微信 yupi1085 咨询星球(备注“想加星球”):
