大家好呀,最近春招开始了,今天给大家分享一些优质面试题及详细解答,希望对正在求职的朋友有所帮助~
后端
题目一
MySQL 事务有哪些隔离级别、分别有什么特点,以及 MySQL 的默认隔离级别是什么?
官方解析
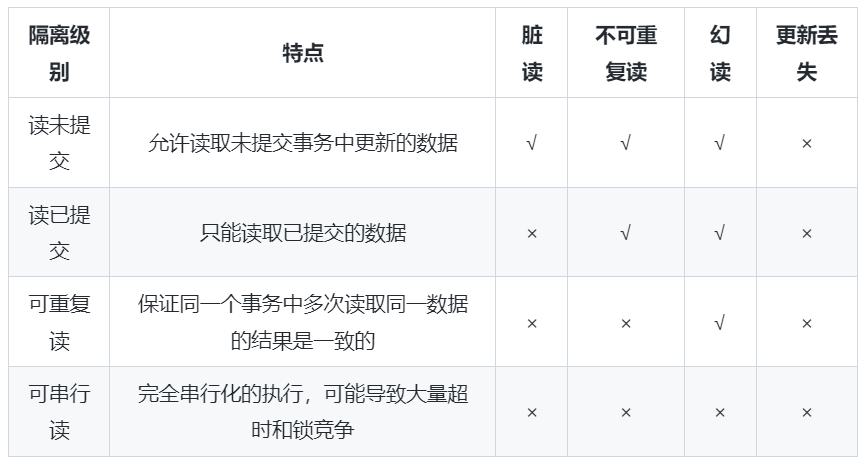
MySQL 事务有四种隔离级别:
读未提交(Read Uncommitted):事务可以读取未提交的数据,可能会读到脏数据,会导致幻读、不可重复读、脏读等问题;
读已提交(Read Committed):只能读取已经提交的数据,可以避免脏读问题,但是可能会遇到不可重复读、幻读问题;
可重复读(Repeatable Read):保证同一个事务中多次读取同一数据的结果是一致的,避免了脏读和不可重复读问题,但是可能会遇到幻读问题;
序列化(Serializable):最高的隔离级别,可以避免所有并发问题,但是并发性能非常低,开销很大。
MySQL 的默认隔离级别是可重复读(Repeatable Read)。
其中,脏读指一个事务读到了另一个事务未提交的数据,不可重复读指同一个事务多次读取同一数据得到不同结果,幻读指同一个事务前后读取的数据集合不一致。
在实际使用中,应该根据具体情况选择合适的隔离级别,权衡数据的一致性和并发性能。
鱼友的精彩回答
苏打饼干的回答
查看隔离级别
SELECT @@TRANSACTION_ISOLATION;
SET [SESSION|GLOBAL] TRANSACTION ISOLATION LEVEL [READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE];
注:mysql 中默认事物隔离级别是可重复读。

爱吃鱼蛋的回答
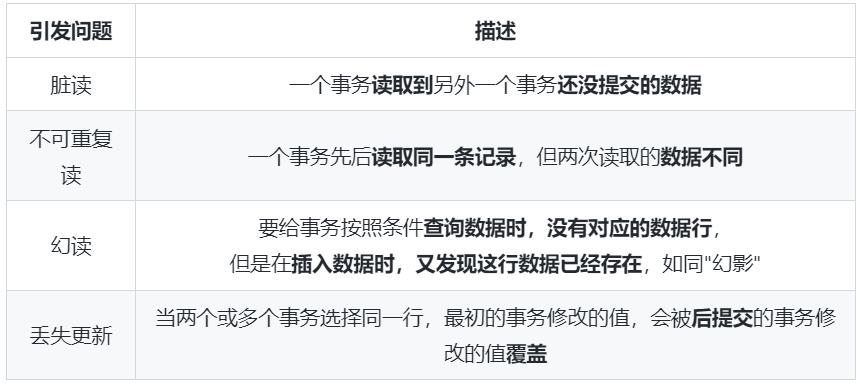
在MySQL中事务的隔离级别是为了解决常见的并发问题,在保证数据库性能的同时保持事务的隔离性,常见的并发问题有:
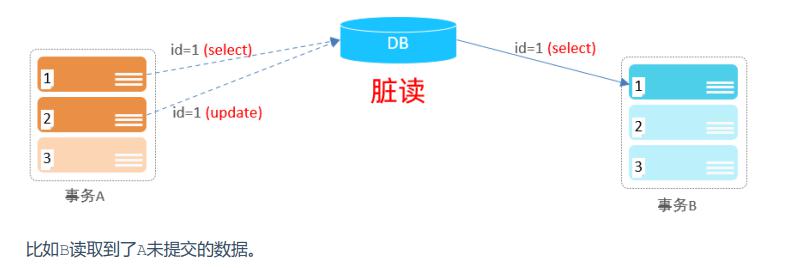
脏读:如果一个事务读到了另一个未提交事务修改过的数据,那就意味着发生了脏读(Dirty Read)。
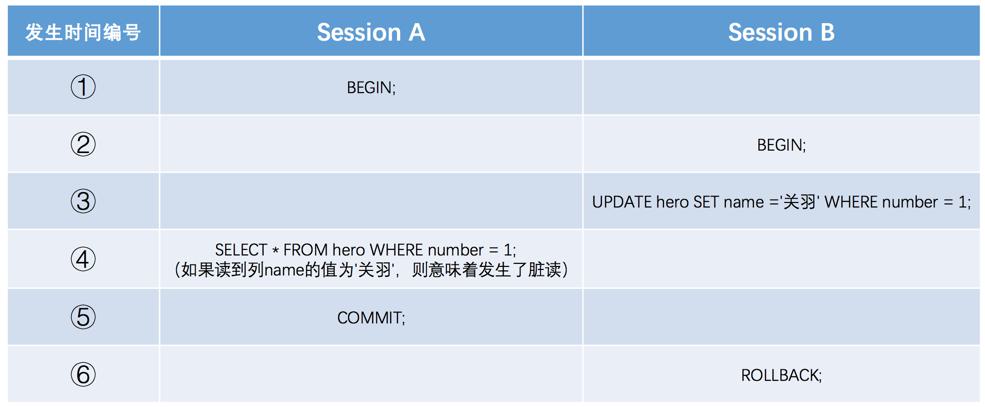
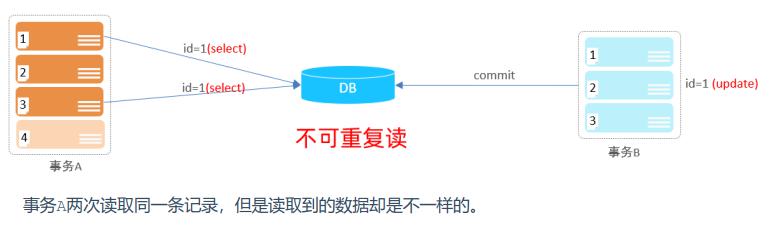
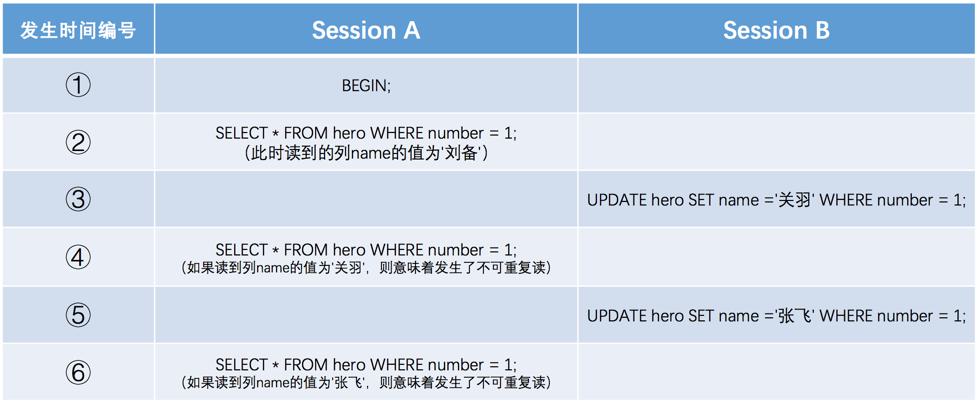
不可重复读:如果一个事务只能读到另一个已经提交的事务修改过的数据,并且其他事务每对该数据进行一次修改并提交后,该事务都能查询得到最新值,那就意味着发生了不可重复读(Non-Repeatable Read);
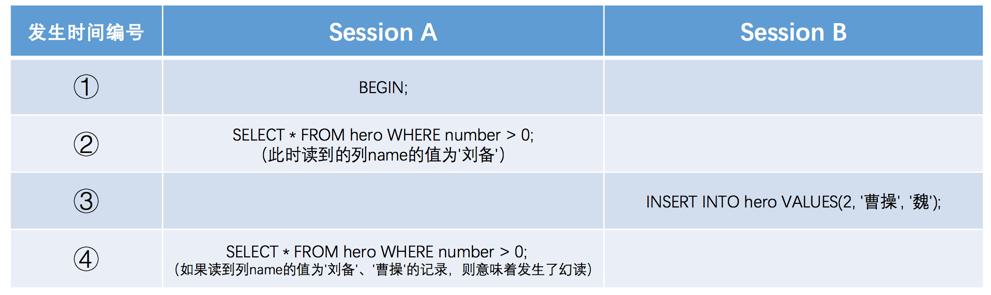
幻读:如果一个事务先根据某些条件查询出一些记录,之后另一个事务又向表中插入了符合这些条件的记录,原先的事务再次按照该条件查询时,能把另一个事务插入的记录也读出来,那就意味着发生了幻读(Phantom reading)。
三个并发问题的区别如下:
脏读的重点在于未提交。脏读应该是三个里面最好理解的,其定义很轻易便能理解,一个事务中读取了另外一个事务未提交的数据,是先修改再读;
不可重复读的重点在于对单条数据读取了两遍。T1先读取了一遍,而后T2修改该数据并提交,最后T1再次读取了该数据发现与之前的不同;
幻读的重点在于针对一类条件对一系列数据读取了两遍。比较特殊的点在于幻读是具备条件的查询,这种查询可能查出来的并不只有一条数据,而在两次查询过程中另外一个事务对查询的结果集中的某条数据进行了变动。
针对于上述的并发问题,在 SQL 标准中设立了以下4个隔离级别:
- READ UNCOMMITTED:未提交读。所有事务都可以看到其他未提交事务的执行结果;
- READ COMMITTED:已提交读。一个事务只能看见已经提交事务所做的改变;
- REPEATABLE READ:可重复读。确保了同一事务的多个实例在并发读取数据时,会看到同样的数据行;
- SERIALIZABLE:可串行化。强制事务串行,并发效率很低。
下面表格展示了在 SQL 标准中规定的并发事务执行过程中可能发生的现象,其中✔️代表可能发生现象,❌代表不可能发生现象:
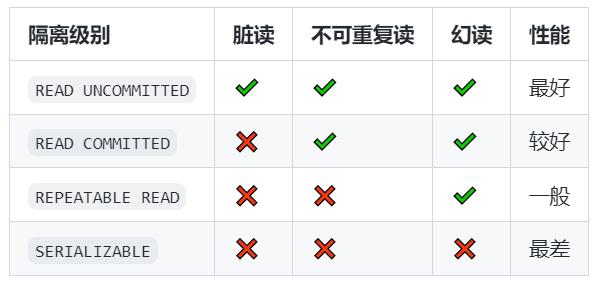
不同的数据库厂商对 SQL 标准中规定的 4 种隔离级别的支持是不一样的。其中 MySQL 的默认隔离级别为 REPEATABLE READ,即可重复读在该隔离级别下可以很大程度上禁止了幻读现象的发生。
林风的回答
SQL 标准提出了四种隔离级别来规避这些现象,隔离级别越高,性能效率就越低,这四个隔离级别如下:
- 读未提交(read uncommitted),指一个事务还没提交时,它做的变更就能被其他事务看到;
- 读已提交(read committed),指一个事务提交之后,它做的变更才能被其他事务看到;
- 可重复读(repeatable read),指一个事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,MySQL InnoDB 引擎的默认隔离级别;
- 串行化(serializable );会对记录加上读写锁,在多个事务对这条记录进行读写操作时,如果发生了读写冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行;
拓展问题
- 不同的隔离级别会有不同的特性,那么为什么要设置这么多的隔离级别呢?
- 不同的隔离级别有哪些实际应用的场景,适合解决什么业务?
- 每个隔离级别是怎么实现的?
不同的隔离界别有哪些实际应用的场景,适合解决什么业务? 不同的隔离级别适用于不同的场景,下面列举一些实际应用:
- 读未提交(read uncommitted):适用于数据实时性要求较高的场景,比如一些报表的生成,当数据量大、计算量大时,如果使用较高的隔离级别,可能会出现锁等待导致查询时间过长的情况,而读未提交隔离级别可以避免这种情况的发生。
- 读已提交(read committed):适用于对数据准确性要求较高的场景,比如金融交易等,由于该隔离级别会在读取时加共享锁,所以可以避免脏读的问题。
- 可重复读(repeatable read):适用于业务场景较为复杂的情况,比如订单下单和支付,如果使用较低的隔离级别可能会导致支付时查询出的订单状态不正确,从而造成数据不一致的问题,而可重复读隔离级别可以避免这种情况的发生。
- 串行化(serializable):适用于对数据完整性要求非常高的场景,比如一些高风险的金融交易,由于该隔离级别会对每个事务加排它锁,所以可以避免幻读和不可重复读的问题。不过需要注意的是,该隔离级别的并发性非常低,会影响系统的性能,一般只在必要的情况下才会使用。
题目二
讲一下 Redis 的单线程模型,IO 多路复用是什么?
官方解析
Redis 是一款基于内存的高性能键值存储系统,采用单线程模型的设计。在 Redis 中,所有客户端的请求都是由一个单线程来处理的,这个单线程不断地从客户端套接字中读取命令请求,并将命令请求放入一个请求队列中。接着,Redis 的事件处理器会按照一定的规则选择一个请求进行处理,处理完之后将响应结果返回给客户端。
单线程模型的优点是可以避免多线程并发访问共享数据时的竞争和死锁问题,简化了系统的设计和调试。此外,由于 Redis 的内存访问速度非常快,因此单线程处理请求也能够保证足够的性能。
IO 多路复用是指在一个线程中同时监听多个文件描述符,一旦某个文件描述符就绪,就立即处理对应的事件。在 Redis 中,采用的是基于 epoll 的 IO 多路复用技术,可以实现高效的事件监听和响应。
在 Redis 中,客户端的请求是由一个单线程来处理的,而 IO 操作却是通过 epoll 多路复用技术实现的。这种设计方式既能充分利用 CPU 的计算能力,又能够保证足够的 IO 处理能力,从而实现了高效的键值存储服务。
鱼皮补充:这题的另一个问法是 “Redis 为什么快?” 建议大家通过画图理解 IO 多路复用
鱼友的精彩回答
林风的回答
Redis实现的单线程并不是一个纯粹的单线程,所谓的单线程指的是Redis在解析客户端发送的命令,处理这样的请求使用的是单线程。
在Redis2.6版本会有后台线程来处理文件关闭、AOF刷盘
Redis 在 4.0 版本之后,新增了一个新的后台线程,用来异步释放 Redis 内存,也就是 lazyfree 线程。
那为什么 Redis 使用的是单线程但是性能还是这么高呢?
IO 多路复用机制指的是一个进程可以处理多个不同任务。
无名的回答
在Redis 6.0以前,Redis的核心网络模型选择用单线程来实现。
对于一个 DB 来说,CPU 通常不会是瓶颈,因为大多数请求不会是 CPU 密集型的,而是 I/O 密集型。具体到 Redis的话,如果不考虑 RDB/AOF 等持久化方案,Redis是完全的纯内存操作,执行速度是非常快的,因此这部分操作通常不会是性能瓶颈,Redis真正的性能瓶颈在于网络 I/O,也就是客户端和服务端之间的网络传输延迟,因此 Redis选择了单线程的 I/O 多路复用来实现它的核心网络模型。
实际上更加具体的选择单线程的原因如下:
避免过多的上下文切换开销:如果是单线程则可以规避进程内频繁的线程切换开销,因为程序始终运行在进程中单个线程内,没有多线程切换的场景。
避免同步机制的开销:如果 Redis 选择多线程模型,又因为 Redis 是一个数据库,那么势必涉及到底层数据同步的问题,则必然会引入某些同步机制,比如锁,而我们知道 Redis不仅仅提供了简单的 key-value 数据结构,还有 list、set 和 hash 等等其他丰富的数据结构,而不同的数据结构对同步访问的加锁粒度又不尽相同,可能会导致在操作数据过程中带来很多加锁解锁的开销,增加程序复杂度的同时还会降低性能。
简单可维护:如果 Redis使用多线程模式,那么所有的底层数据结构都必须实现成线程安全的,这无疑又使得 Redis的实现变得更加复杂。
总而言之,Redis选择单线程可以说是多方博弈之后的一种权衡:在保证足够的性能表现之下,使用单线程保持代码的简单和可维护性。
IO多路复用
IO 多路复用是指内核一旦发现进程指定的一个或者多个 IO 条件准备读取,它就通知该进程。
IO多路复用适用如下场合:
- 当客户处理多个描述字时(一般是交互式输入和网络套接口),必须使用I/O复用。
- 当一个客户同时处理多个套接口时,而这种情况是可能的,但很少出现。
- 如果一个TCP服务器既要处理监听套接口,又要处理已连接套接口,一般也要用到I/O复用。
- 如果一个服务器即要处理TCP,又要处理UDP,一般要使用I/O复用。
- 如果一个服务器要处理多个服务或多个协议,一般要使用I/O复用。
- 与多进程和多线程技术相比,I/O多路复用技术的最大优势是系统开销小,系统不必创建进程/线程,也不必维护这些进程/线程,从而大大减小了系统的开销。
题目三
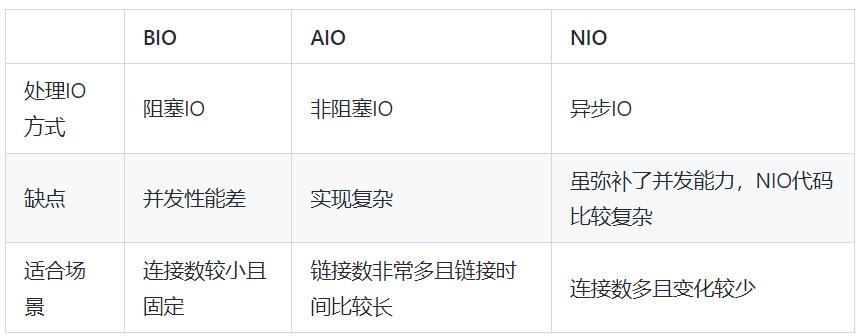
什么是 BIO、NIO、AIO?
官方解析
BIO、NIO、AIO 都是 Java 的 IO 模型。
BIO (Blocking IO) 是传统的 IO 模型,它在读写数据时会阻塞线程,直到数据读写完成,适用于并发不高的场景。
NIO (Non-blocking IO) 是 Java 的新 IO 模型,它在读写数据时不会阻塞线程,而是通过轮询的方式检查是否有数据可读写,适用于并发量较高的场景。
AIO (Asynchronous IO) 是 JDK 7 开始引入的新 IO 模型,它的读写方式与 NIO 相似,但在读写数据时,不需要自己手动轮询是否有数据可读写,而是交由系统完成,适用于高并发且处理较大数据量的场景。
总的来说,BIO 的并发处理能力较差,NIO 的并发处理能力较好,但使用起来较为复杂,AIO 的并发处理能力最好,但也是最为复杂的一种 IO 模型。选择适合自己场景的 IO 模型是非常重要的。
鱼皮补充:这题比较建议大家举一个例子来区分这些概念,比如:人等待水壶烧水
鱼友的精彩回答
一切总会归于平淡的回答
BIO、NIO、AIO 是 Java 中常用的 I/O 模型,它们都是针对网络编程中 I/O 操作的不同实现方式。
BIO,全称 Blocking I/O,也称为同步阻塞 I/O。
BIO 是最早的 I/O 模型,它是一种阻塞式的 I/O 模型,即当应用程序调用 I/O 操作时,该操作会一直阻塞线程直到操作完成,这会导致 I/O 性能低下。BIO 适用于连接数较小的场景,例如单线程的服务器模型。
NIO,全称 Non-Blocking I/O,也称为同步非阻塞 I/O。
NIO 是一种同步非阻塞的 I/O 模型,它的核心是 Selector 和 Channel,利用 Selector 监听多个 Channel 上的事件,当一个 Channel 上的事件到达时,它会被 Selector 转发给注册在这个 Selector 上的其他 Channel,这样可以用一个线程来处理多个请求,提高了 I/O 的效率。NIO 适用于连接数多、连接时间短的场景,例如实时聊天室、在线游戏等。
AIO,全称 Asynchronous I/O,也称为异步非阻塞 I/O。AIO 是 JDK1.7 引入的 I/O 模型,它的特点是异步处理 I/O 操作,当操作完成时会通知应用程序,相比于 NIO 的同步非阻塞 I/O,AIO 无需通过轮询操作完成状态,从而提高了 I/O 的效率。AIO 适用于连接数多、连接时间长的场景,例如 HTTP 长连接、文件操作等。
面试官问到这个问题,可能想了解你对 Java 中不同的 I/O 模型的了解程度,以及你能否根据不同的业务需求选择合适的 I/O 模型。同时,他可能还想了解你在实际开发中使用过哪些 I/O 模型,以及它们的应用场景。
猫十二懿的回答
BIO、NIO、AIO 都是 Java 中网络编程的 I/O 模型。
BIO(Blocking IO )是JDK1.4之前的传统IO模型,特点就是同步阻塞等待数据,直到数据读取完毕才会返回结果,线程会一直阻塞在 read/write 方法上,不能处理其他的 IO 请求,它的并发性能比较差。
NIO(Non-Blocking IO)是Java 1.4 之后新增的 IO 模型,它支持同步非阻塞式的 IO 操作。NIO 采用了多路复用器来处理 IO 请求,通过一个线程处理多个 IO 请求,实现了高并发处理。NIO 主要有三个核心概念:Selector、Channel、Buffer。Selector 负责监听多个 Channel 上的事件,Channel 可以理解为对原始 IO 的封装,Buffer 则是对数据的封装。
AIO(Asynchronous IO)是Java 1.7 之后新增的 IO 模型,它支持异步非阻塞 IO 操作。与 NIO 不同的是,AIO 在进行读写操作时不需要像 NIO 一样一直轮询,而是通过回调函数的方式在数据准备好后通知应用程序进行数据的读取,这样可以更加高效地利用系统资源,提高吞吐量。但是 AIO 在处理小文件和小数据量时的性能并不如 NIO。
三者区别
白小军的回答
BIO 同步阻塞 IO,即打算约女神,给女神发短信后,没见到女神就一直等在宿舍楼下。
NIO 同步非阻塞 IO,即打算约女神,给女神发短信后,没见到女神就一直发短信。
NIO java中的 NIO,就是打算约女神,你让宿管大妈去挨个看每一个下楼的妹子,女神下楼了大妈就通知你。
AIO 就是打算约女神,你发完短信,你就去玩游戏了,女神下楼了,发短信给你,你才出现。
前端
题目一
前端有哪些实现跨页面通信的方法?
官方解析
前端有以下几种实现跨页面通信的方法:
Cookie:通过在页面间共享 Cookie 实现简单的跨页面通信,但是 Cookie 大小有限制,不能存储过多的数据。
localStorage 和 sessionStorage:HTML5 提供了本地存储的能力,可以通过 localStorage 或 sessionStorage 实现页面间数据共享,相比 Cookie 更加方便,但是也有大小限制。
BroadcastChannel API:这是一个 HTML5 新增的 API,允许多个页面间通信,可以广播消息或向特定页面发送消息。
SharedWorker:SharedWorker 是一种特殊类型的 Web Worker,可以在多个页面间共享数据,可以通过 postMessage API 实现消息传递。
postMessage API:这是 HTML5 提供的一种消息传递机制,可以在不同窗口或 iframe 间传递消息,可以用来实现跨域通信。
WebSocket:WebSocket 是一种持久化的协议,可以在浏览器和服务器之间实现双向通信,也可以在不同页面之间实现通信。
以上这些方法都有其适用的场景和限制条件,需要根据具体情况进行选择和使用。
鱼友的精彩回答
codexgh 的回答
当我们在浏览器中打开很多页面的时,如果我们对一个页面上的数据进行了修改操作,而跟这个数据相关的其它页面也能够实时的修改页面上的数据,这个就是跨页面通信。跨页面通信可分为同源和非同源:
同源页面之间通信:BroadCast Channel: BroadCast Channel官方定义为该API适用于同源不同页面之间完成通信的功能。BroadCast Channel可以帮助我们创建一个用于广播的通信频道,当所有页面都监听同一频道时,其中某一个页面通过他发送消息就会被其它页面接收到:
// 创建
const a = new BroadcastChannel(temp);
// 发送消息
a.postMessage("hello")
// 关闭
a.close()
// 监听
a.onmessage = function(e){
console.log("监听到了:", e)
}
// 错误监听
a.onmessageerror = function(err){
console.log("error", err)
}
ServiceWorker:ServiceWorker是一个可以长期运行在后台的worker,能够实现与页面之间的双向通信。多页面的serviceWorker可以共享,将serviceWorker作为消息处理中心,即可实现广播效果;service worker跟BoardCast Channel相似之处在于两者都是使用了广播的方式完成跨页面通信;而service worker不同的点在于,它本身不具备广播通信的功能,我们需要再配置service worker ,将其改造成消息中转站;
localStorage: 当localStorage发生变化时,会触发storage事件,利用这个特性,我们在发送消息的时候,把信息写入localStorage中,然后在各个页面中,我们监听storage事件即可完成跨页面通信;当某个页面需要发送消息的时候,只需要使用setItem方法即可。
window.open+window.opener: 当我们使用window.open打开一个页面时,我们会建立起一个树形结构,当我们需要发送消息时,作为消息的发起方,一个页面需要同时通知它打开的页面和打开它的页面;被打开的页面,可以通过window.opener来获取打开他的页面的引用;这样每一个页面节点都肩负起来了传递消息额的责任;但是这种方式存在一个问题:如果页面不是通过另一个页面的window.open打开的,例如直接在地址栏输入,或从其他网站链接过来,这个树状结构就不可行了;
非同源页面之间通信:iframe+postMessage():要实现非同源跨页面通信,我们可以使用一个用户不可见的iframe作为“桥”,由于iframe与父页面间可以通过postMessage()忽略同源限制,因此可以在每个页面嵌入一个iframe,而这些iframe由于是使用的同一个url,因此是属于同源页面,就可以使用同源页面通信的方法了。
mos 的回答
const targetWindow = window.open('http://example.com/');
targetWindow.postMessage('Hello, target window!', 'http://example.com/');
要在接收端接收消息,可以将以下代码添加到接收窗口的脚本中:
window.addEventListener('message', function(event) {
if (event.origin !== 'http://example.com/') { return; }
console.log(event.data);
});
我们通过添加一个事件侦听器来监听接收消息。event 对象包含 event.data 属性,它包含发送方发送的实际消息内容。接收方可以通过验证 event.origin 属性,以确保消息来自预期的源,从而确保安全性。6. WebSocket:WebSocket 是一种持久化的协议,可以在浏览器和服务器之间实现双向通信,也可以在不同页面之间实现通信。并且数据传输速度较快.
题目二
TypeScript 的内置数据类型有哪些?
官方解析
TypeScript 的内置数据类型包括:
鱼友的精彩回答
H.lj????ᯤ⁶ᴳ的回答
TypeScript 是 JavaScript 的超集,它在 JavaScript 的基础上增加了类型系统。TypeScript 提供了与 JavaScript 相同的数据类型,同时还增加了一些额外的类型。TypeScript 的内置数据类型如下:
除了以上内置类型,TypeScript 还支持定义自定义类型和联合类型等高级类型。
题目三
什么是虚拟 DOM?使用虚拟 DOM 一定更快吗?
官方解析
虚拟 DOM(Virtual DOM)是一种将浏览器 DOM 抽象为 JavaScript 对象的技术,用于提高 DOM 操作的效率和性能。虚拟 DOM 可以在渲染前对组件的变化进行计算,减少 DOM 操作的次数,从而提高渲染性能。
使用虚拟 DOM 可以提高性能,但并不是一定更快。虚拟 DOM 需要进行额外的计算和比较操作,而这些操作也会消耗一定的时间和性能。因此,虚拟 DOM 适用于大规模、高度动态的页面,而在简单的静态页面中使用虚拟 DOM 并不能提高性能。此外,虚拟 DOM 还可以提高开发效率,使代码更易于维护和调试。
鱼友的精彩回答
codexgh 的回答
虚拟DOM是一个 js对象,一个什么样的对象呢?一个用来表示真是DOM的对象,要记住这句话,举个例子,请看一下真实DOM:
<ul id="list">
<li class="item">哈哈</li>
<li class="item">嘿嘿</li>
<li class="item">呵呵</li>
</ul>
对应的虚拟DOM为:
let oldVDOM = { // 旧虚拟DOM
tagName: 'ul', // 标签名
props: { // 标签属性
id: 'list'
},
children: [ // 标签子节点
{
tagName: 'li', props: { class: 'item' }, children: [ '哈哈' ]
},
{
tagName: 'li', props: { class: 'item' }, children: [ '嘿嘿' ]
},
{
tagName: 'li', props: { class: 'item' }, children: [ '呵呵' ]
},
]
}
这个时候,修改一个li标签的文本:
<ul id="list">
<li class="item">哈哈</li>
<li class="item">嘿嘿</li>
<li class="item">快来学习Diff算法了,呵呵</li>
</ul>
这个时候生成的新虚拟DOM为:
let newVDOM = { // 新虚拟DOM
tagName: 'ul', // 标签名
props: { // 标签属性
id: 'list'
},
children: [ // 标签子节点
{
tagName: 'li', props: { class: 'item' }, children: [ '哈哈' ]
},
{
tagName: 'li', props: { class: 'item' }, children: [ '嘿嘿' ]
},
{
tagName: 'li', props: { class: 'item' }, children: [ '快来学习Diff算法了,呵呵' ]
},
]
}
这就是我们平常说的新旧两个虚拟DOM,这个时候的新虚拟DOM是数据的最新状态,那么我们直接拿新虚拟DOM去渲染成真实DOM的话,效率真的要比直接操作真实DOM高吗?那肯定是不会的,如图所示:
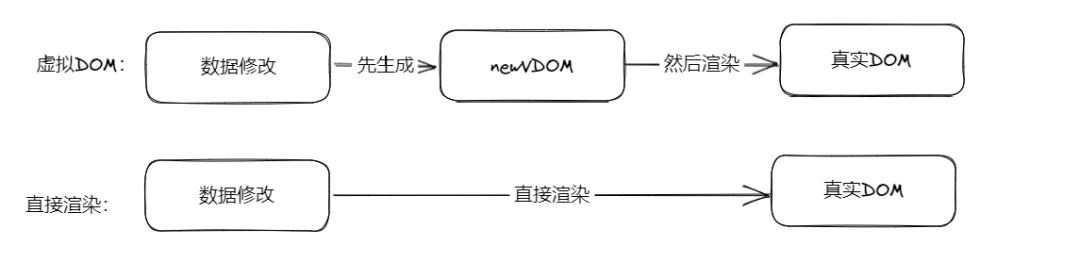
从图中一看便知,肯定是第2种方式比较快,因为第1种方式中间还夹着一个虚拟DOM的步骤,所以虚拟DOM比真实DOM快 这句话是错的,或者说不严谨。正确的说法应该是:虚拟DOM算法操作真实DOM,性能高于直接操作DOM,虚拟DOM和虚拟DOM算法是两种概念。虚拟DOM算法 = 虚拟DOM + Diff算法
Kristen 的回答
因为操作DOM会引起页面的回流或者重绘,而这两个东西是非常耗费性能的。因此我们越少操作真实dom就越好。相比起来,通过多一些预先计算来减少DOM的操作要划算的多。
虚拟DOM是通过JS对象模拟出来的DOM节点,domDiff是通过特定算法计算出来一次操作所带来的DOM变化。减少 DOM 操作的次数,从而提高渲染性能。可以提高开发效率
但是,“使用虚拟DOM会更快”这句话并不一定适用于所有场景。例如:一个页面就有一个按钮,点击一下,数字加一,那肯定是直接操作DOM更快。虚拟 DOM 需要进行额外的计算和比较操作,而这些操作也会消耗一定的时间和性能。即使是复杂情况,浏览器也会对我们的DOM操作进行优化,大部分浏览器会根据我们操作的时间和次数进行批量处理,所以直接操作DOM也未必很慢。
mos 的回答
一、什么是虚拟DOM
实际上它只是一层对真实DOM的抽象,以JavaScript 对象 (VNode 节点) 作为基础的树,用对象的属性来描述节点,最终可以通过一系列操作使这棵树映射到真实环境上
在Javascript对象中,虚拟DOM 表现为一个 Object对象。并且最少包含标签名 (tag)、属性 (attrs) 和子元素对象 (children) 三个属性,不同框架对这三个属性的名命可能会有差别
创建虚拟DOM就是为了更好将虚拟的节点渲染到页面视图中,所以虚拟DOM对象的节点与真实DOM的属性一一照应
vue中虚拟DOM技术 定义真实DOM
<div id="app">
<p class="p">节点内容</p>
<h3>{{ foo }}</h3>
</div>
实例化vue
const app = new Vue({
el:"#app",
data:{
foo:"foo"
}
})
观察render,得到虚拟DOM
(function anonymous(
) {
with(this){return _c('div',{attrs:{"id":"app"}},[_c('p',{staticClass:"p"},
[_v("节点内容")]),_v(" "),_c('h3',[_v(_s(foo))])])}})
通过VNode,vue可以对这颗抽象树进行创建节点,删除节点以及修改节点的操作, 经过diff算法得出一些需要修改的最小单位,再更新视图,减少了dom操作,提高了性能
二、使用虚拟DOM的原因
DOM是很慢的,其元素非常庞大,页面的性能问题,大部分都是由DOM操作引起的
真实的DOM节点,哪怕一个最简单的div也包含着很多属性,可以打印出来直观感受一下:

由此可见,操作DOM的代价仍旧是昂贵的,频繁操作还是会出现页面卡顿,影响用户的体验
举个例子:
你用传统的原生api或jQuery去操作DOM时,浏览器会从构建DOM树开始从头到尾执行一遍流程
当你在一次操作时,需要更新10个DOM节点,浏览器没这么智能,收到第一个更新DOM请求后,并不知道后续还有9次更新操作,因此会马上执行流程,最终执行10次流程
而通过VNode,同样更新10个DOM节点,虚拟DOM不会立即操作DOM,而是将这10次更新的diff内容保存到本地的一个js对象中,最终将这个js对象一次性attach到DOM树上,避免大量的无谓计算
很多人认为虚拟 DOM 最大的优势是 diff 算法,减少 JavaScript 操作真实 DOM 的带来的性能消耗。虽然这一个虚拟 DOM 带来的一个优势,但并不是全部。虚拟 DOM 最大的优势在于抽象了原本的渲染过程,实现了跨平台的能力,而不仅仅局限于浏览器的 DOM,可以是安卓和 IOS 的原生组件,可以是近期很火热的小程序,也可以是各种GUI
三、如何实现虚拟DOM 首先可以看看vue中VNode的结构
源码位置:src/core/vdom/vnode.js
export default class VNode {
tag: string | void;
data: VNodeData | void;
children: ?Array<VNode>;
text: string | void;
elm: Node | void;
ns: string | void;
context: Component | void; // rendered in this component's scope
functionalContext: Component | void; // only for functional component root nodes
key: string | number | void;
componentOptions: VNodeComponentOptions | void;
componentInstance: Component | void; // component instance
parent: VNode | void; // component placeholder node
raw: boolean; // contains raw HTML? (server only)
isStatic: boolean; // hoisted static node
isRootInsert: boolean; // necessary for enter transition check
isComment: boolean; // empty comment placeholder?
isCloned: boolean; // is a cloned node?
isOnce: boolean; // is a v-once node?
constructor (
tag?: string,
data?: VNodeData,
children?: ?Array<VNode>,
text?: string,
elm?: Node,
context?: Component,
componentOptions?: VNodeComponentOptions
) {
/*当前节点的标签名*/
this.tag = tag
/*当前节点对应的对象,包含了具体的一些数据信息,是一个VNodeData类型,可以参考VNodeData类型中的数据信息*/
this.data = data
/*当前节点的子节点,是一个数组*/
this.children = children
/*当前节点的文本*/
this.text = text
/*当前虚拟节点对应的真实dom节点*/
this.elm = elm
/*当前节点的名字空间*/
this.ns = undefined
/*编译作用域*/
this.context = context
/*函数化组件作用域*/
this.functionalContext = undefined
/*节点的key属性,被当作节点的标志,用以优化*/
this.key = data && data.key
/*组件的option选项*/
this.componentOptions = componentOptions
/*当前节点对应的组件的实例*/
this.componentInstance = undefined
/*当前节点的父节点*/
this.parent = undefined
/*简而言之就是是否为原生HTML或只是普通文本,innerHTML的时候为true,textContent的时候为false*/
this.raw = false
/*静态节点标志*/
this.isStatic = false
/*是否作为跟节点插入*/
this.isRootInsert = true
/*是否为注释节点*/
this.isComment = false
/*是否为克隆节点*/
this.isCloned = false
/*是否有v-once指令*/
this.isOnce = false
}
// DEPRECATED: alias for componentInstance for backwards compat.
/* istanbul ignore next https://github.com/answershuto/learnVue*/
get child (): Component | void {
return this.componentInstance
}
}
这里对 VNode 进行稍微的说明:
所有对象的 context 选项都指向了 Vue 实例 elm 属性则指向了其相对应的真实 DOM 节点 vue是通过createElement生成VNode
小结
createElement 创建 VNode 的过程,每个 VNode 有 children,children 每个元素也是一个VNode,这样就形成了一个虚拟树结构,用于描述真实的DOM树结构.
使用虚拟 DOM 可以提高性能,但并不是一定更快。虚拟 DOM 需要进行额外的计算和比较操作,而这些操作也会消耗一定的时间和性能。因此,虚拟 DOM 适用于大规模、高度动态的页面,而在简单的静态页面中使用虚拟 DOM 并不能提高性能。此外,虚拟 DOM 还可以提高开发效率,使代码更易于维护和调试。
星球活动
1.欢迎参与 ,搞定高频面试题,斩杀面试官!
2.欢迎已加入星球的同学 !
3.欢迎学习 ,手把手教你做出项目、写出高分简历!
加入我们
欢迎加入鱼皮的,鱼皮会 1 对 1 回答您的问题、直播带你做出项目、为你定制学习计划和求职指导,还能获取海量编程学习资源,和上万名学编程的同学共享知识、交流进步。
???? 加入星球后,您可以:
1)添加鱼皮本人微信,向他 1 对 1 提问,帮您解决问题、告别迷茫!
2)获取海量编程知识和资源,包括:3000+ 鱼皮的编程答疑和求职指导、原创编程学习路线、几十万字的编程学习知识库、几十 T 编程学习资源、500+ 精华帖等!

3)找鱼皮咨询求职建议和优化简历,次数不限!

4)鱼皮直播从 0 到 1 带大家做出项目,已有 50+ 直播、完结 3 套项目、10+ 项目分享,帮您掌握独立开发项目的能力、丰富简历!
外面一套项目课就上千元了,而星球内所有项目都有指导答疑,轻松解决问题
星球提供的所有服务,都是为了帮您更好地学编程、找到理想的工作。诚挚地欢迎您的加入,这可能是最好的学习机会,也是最值得的一笔投资!
长按扫码领优惠券加入,也可以添加微信 yupi1085 咨询星球(备注“想加星球”):

往期推荐